Джерард Уильямс III, ведущий дизайнер собственных чипов Apple для iOS от A7 до A12X, покинул компанию, сообщает CNET. Хотя в его профиле в LinkedIn нет никаких указаний на изменения, он дает представление о его дизайнере.
Уильямс присутствовал в истории устройств Apple еще раньше, так как он был техническим руководителем дизайна Cortex-A8, первого суперскалярного ядра ARM и сердца iPhone 3GS. Его роль, очевидно, росла с годами, и обязанности по архитектуре ЦП в конечном итоге переросли во владение всей системой на чипе (SoC), которая включает в себя ЦП, графику, обработку изображений, безопасный анклав, а также ядра для обработки движения и искусственного интеллекта.
Взгляд на его портфолио патентов показывает, что он был ключевой фигурой в выходе Apple на рынок кластеров смешанных ядер ЦП, начиная с чипа A10 Fusion и переходя к полностью гетерогенным ядрам с A11 Bionic. Его работа также включает акцент на кэш-память, память и энергоэффективность. Они стали ключевыми отличительными чертами, как показали результаты тестирования производительности на таких сайтах, как AnandTech.
Он пришел в Apple с шумом, так как A7 был первым 64-битным ядром ЦП от Apple. Эта разработка появилась на рынке более чем за год до того, как конкуренты, такие как Qualcomm и Samsung, смогли отреагировать, и в значительной степени закрепила техническое превосходство команды SoC, созданной Apple.
Если это подтвердится, его уход последует за более известным архитектором ЦП Джимом Келлером, который был частью приобретения Apple компании PA Semi. Совсем недавно команда Apple SoC потеряла своего ведущего Ману Гулати, чью освободившуюся должность занял Уильямс. Однако Apple добилась некоторого успеха в удержании ключевых технических руководителей, поскольку недавние слухи о кандидатуре старшего вице-президента по аппаратным технологиям Джонни Сручи на пост генерального директора Intel не оправдались. Apple также удалось удержать Боба Мэнсфилда, несмотря на то, что объявила о его выходе на пенсию.
Что касается потенциальных мест назначения, Intel стала излюбленным местом для высокопоставленных технических руководителей, поскольку они привлекли многих ключевых руководителей AMD, а также бывшего руководителя Apple Джима Келлера. Intel также поглощает членов прессы, стремясь вернуть свое техническое лидерство в отрасли, принимая на работу многолетних писателей PC Perspective, включая главного редактора Райана Шраута.
Пользователь, опубликовавший информацию на reddit и на форумах MacRumors, подробно рассказал о своих находках и попытках обойти троттлинг, ранее обнаруженный в новых моделях MacBook Pro 15″, оснащенных шестиядерными процессорами Intel i9.
Пользователь далее объясняет, что один из внутренних лимитов питания, установленных для устройства, может не соответствовать энергопотреблению процессора и аналогичен предыдущим моделям MacBook Pro, что приводит к тому, что чип управления питанием (известный как модуль регулирования напряжения, или VRM) сообщает об условиях перегрузки по мощности, которые вынуждают снижать тактовую частоту процессора для уменьшения энергопотребления. Это создает те же условия для возникновения троттлинга.
Эти условия могут возникать из-за новой шестиядерной конструкции процессора i9, представленной здесь. Хотя Intel увеличила количество ядер процессора, она не увеличила расчетную тепловую мощность (TDP) или объем рассеиваемой мощности, которые производители должны планировать для надлежащего охлаждения при разработке процессора. Это проблема, поскольку это число обычно отражает нормальное использование и не учитывает турбо-режимы. Вероятно также, что оно может превышать потребление предыдущих четырехъядерных процессоров, учитывая сходство тактовых частот и техпроцессов, на которых они реализованы.
В публикации предлагается метод настройки этого лимита, но он требует ручного выполнения команды или выполнения скрипта каждый раз при загрузке компьютера, и, скорее всего, аннулирует гарантию, если бы технические специалисты Apple обнаружили его. Тем не менее, пользователь публикует результаты тестов, показывающие последовательные запуски без троттлинга. Производители всегда будут указывать на вероятное снижение срока службы компонентов при использовании вне их спецификаций, но результаты выглядят стабильными, и отсутствует тепловой троттлинг процессора, который изначально подозревался как причина проблемы.
Это исправление не устранит избыточное общее потребление мощности системой, например, при длительных нагрузках от процессора и графического процессора, но вполне возможно, что Apple выпустит исправление, аналогичное тому, что описано в посте на Reddit, которое будет стабильным.
Что касается того, связана ли эта проблема с аппаратным дизайном MacBook Pro, то и это возможно. Хотя полная разборка текущего 15-дюймового MacBook Pro от iFixit еще не доступна, предыдущая разборка выявила существенные различия в чипах VRM, которые питают графический процессор и центральный процессор устройства.
Компоненты питания графического процессора
Компоненты питания графического процессора, показанные выше, расположены на верхней стороне системной платы рядом с кристаллом графического процессора, а на компонентах видна термопаста, что указывает на их взаимодействие с радиатором устройства. Это контрастирует с теми же компонентами для центрального процессора, которые расположены на задней стороне системной платы без теплового интерфейса с верхней частью корпуса, как показано ниже.
Компоненты питания центрального процессора
Кроме того, общедоступные технические характеристики этих частей указывают на большее количество отличий, предполагающих, что их тепловые профили будут разными. Часть International Rectifier для графического процессора имеет более низкое тепловое сопротивление, что означает, что она может лучше рассеивать тепло в окружающие области (плату, воздух, радиатор), чем часть Intersil для центрального процессора. Кроме того, она отличается более высокой энергоэффективностью, что означает, что она сама рассеивает меньше энергии для обеспечения того же количества мощности, что и часть Intersil.
Вместе с путем отвода тепла, предусмотренным для частей IR, становится ясно, что они не смогут выдерживать такую же нагрузку в любом стационарном режиме. Это имеет смысл, учитывая, что графические процессоры могут испытывать высокие нагрузки в течение более длительных периодов, но это может стать областью для улучшения в будущих моделях MacBook Pro от Apple, особенно учитывая, что она обычно выбирает графические процессоры с очень похожими пределами расчетной тепловой мощности (TDP) по сравнению с центральными процессорами в своей линейке MacBook Pro.
Постоянное стремление Apple к повышению производительности, увеличению времени автономной работы и созданию более тонких корпусов, по-видимому, стимулирует ее исследования в области передовых технологий упаковки чипов. Так называемые методы упаковки «2.5D» и «3D» могут обеспечить значительные преимущества во всех этих областях за счет увеличения пропускной способности памяти, снижения энергопотребления и освобождения места для аккумуляторов большей емкости.
Apple является активным пользователем новых методов упаковки устройств, в основном благодаря инновациям в области интегрированного внешнего монтажа (InFO), предоставляемым партнером-литейщиком TSMC. Успех TSMC подтолкнул ее к дальнейшему развитию и диверсификации предложений по упаковке, и TSMC стала лидером отрасли в технологиях упаковки.
Хотя версии упаковки InFO от TSMC привели к повышению производительности устройств Apple, таким как лучшее управление тепловым режимом и улучшенная высота корпуса, они в значительной степени не способствовали повышению электрических характеристик. Это должно измениться с будущими методами упаковки, и уже наблюдается в некоторых продуктах, которые используют интерпозеры для высокоплотных межсоединений с памятью на кристалле, такой как память с высокой пропускной способностью (HBM).
Основным кандидатом на включение в такой корпус будет память, соответствующая стандартам Wide I/O, описанным JEDEC, и упомянутым по имени в нескольких патентах. Эта память превосходит LPDDR4 за счет увеличения количества каналов и снижения скорости передачи данных на канал, тем самым увеличивая общую пропускную способность, но снижая энергию, необходимую на бит.
Однако интерпозеры создают несколько проблем для мобильных устройств. Важно отметить, что они добавляют еще один вертикальный элемент к корпусу, увеличивая общую высоту. Интерпозеры также должны изготавливаться на кремниевых пластинах, как и активные ИС, причем их размеры определяются площадью всех устройств, которые необходимо включить в корпус. Эти решения обычно называют «2.5D» из-за того, что некоторые компоненты расположены в боковом направлении относительно друг друга, а не являются истинным стекированием чипов.
Вместо того чтобы использовать интерпозеры для своих продуктов в качестве следующего шага в передовой упаковке, направление фокуса Apple, согласно нескольким патентным заявкам [1][2][3][4], похоже, заключается в истинных «3D» технологиях, когда логические кристаллы, такие как память, размещаются непосредственно поверх активной SoC. Кроме того, патентная заявка от TSMC, по-видимому, предполагает определенный уровень координации между Apple и TSMC в этих усилиях.
Поток технологического процесса 3D-стекирования
Процесс имеет сходство с существующими технологиями InFO, поскольку оба они включают слой перераспределения (RDL), где контакты на логическом кристалле маршрутизируются внутри компаунда с помощью переходных отверстий непосредственно в компаунде. Отличие 3D-процесса заключается в том, что теперь RDL находится на обеих сторонах кристалла, что требует использования сквозных кремниевых переходных отверстий (TSV) непосредственно в логическом кристалле для обеспечения межсоединений с верхней частью кристалла. Ключевой особенностью этих RDL-слоев является возможность создания более тонких шагов межсоединений, чем доступные на подложке или интерпозере.
Последующие кристаллы затем могут быть прикреплены к компаунду, соединяясь с переходными отверстиями и RDL, расположенными на предыдущем этапе. Этот этап может выполняться многократно, при условии, что каждый собранный компонент имеет TSV для следующего уровня интеграции, и это уже наблюдается в HBM, которая позволяет стекировать до восьми кристаллов DRAM.
Вид сбоку кристалла памяти (110), присоединенного к SoC (150) в 3D-корпусе
Тем не менее, этот подход имеет много технических проблем, которые препятствовали его коммерциализации. TSV дороги во внедрении и являются серьезным фактором снижения выхода ИС. Электрическая изоляция от излучаемой энергии соседних компонентов также может быть проблемой, особенно при интеграции РЧ и аналоговых компонентов в корпус с другими компонентами, которые ранее были разделены пространством и экранированием ЭМП. Apple описывает методы интеграции экранирования непосредственно в корпус для смягчения этой проблемы.
Корпус со встроенным экраном ЭМП
Этот подход также создает тепловые проблемы, поскольку активные кристаллы становятся настолько тесно связанными в средах с плохой теплопроводностью и общими тепловыми путями. Эти проблемы распространяются не только на нормальное использование устройства, но и на интеграцию корпуса и любые этапы пайки оплавлением. Тепловые напряжения могут вызывать коробление компонентов корпуса из-за различных коэффициентов теплового расширения (CTE) материалов, используемых в корпусе. Это коробление может привести к разрыву или разделению контактов, что приведет к отказу устройства.
Использование несущей подложки в технологическом процессе смягчает некоторые тепловые проблемы. Прямая интеграция радиаторов в упаковку устройств также рассматривается на различных уровнях сборки корпуса, таким образом, что кристаллы с более высоким тепловыделением, такие как SoC с ядрами CPU и GPU, могут быть размещены в нижней части стека или на более высоком уровне интеграции, обеспечивая гибкость стекирования, невиданную в предыдущих конфигурациях PoP.
Корпус со встроенным компонентом радиатора (310)
Реализации могут применяться в таких приложениях, как, но не только, низкое энергопотребление и/или архитектура памяти с широкой полосой пропускания ввода-вывода. Реализации могут обеспечить короткий канал с удвоенной скоростью передачи данных (DDR) для соседних функциональных блоков (например, SoC, чипсетов и т. д.) за счет использования RDL и прямого крепления чипов. Реализации могут быть особенно применимы для мобильных приложений, которые требуют низкого энергопотребления DDR при целевой производительности, включая высокую скорость и широкую полосу пропускания ввода-вывода.
Преимущества описанных методов многочисленны. Использование памяти с более высокой пропускной способностью приведет к улучшению производительности. Гибкость размещения компонентов сокращает расстояние между подключенными активными и пассивными устройствами, либо снижая энергию, необходимую для связи между ними, либо уменьшая паразитные эффекты, которые могут вызывать нежелательную потерю мощности или деградацию динамической производительности. Наиболее заметными задачами, которые выиграют, являются игры и обработка изображений, которые часто требуют большого объема данных за короткие промежутки времени.
Связь с Apple Watch
Эти улучшения были бы применимы ко всем мобильным устройствам Apple, но в нескольких патентных заявках конкретно упоминаются методы объединения нескольких компонентов в Системе в Корпусе (SiP), как это видно в текущих Apple Watch. Описанные ниже методы являются улучшением существующих решений SiP, используемых в Apple Watch, поскольку они представляют собой истинные элементы 3D-стекирования, реализованные как через TSV, так и через сквозные оксидные переходные отверстия (TOV).
Массив TOV для соединения стекированных кристаллов с выводами корпуса
В одном аспекте реализации описывают разделение на кристаллах системы на кристалле (SoC) и/или разделение кристаллов в структуре SiP (например, 3D-корпус памяти), в которой IP-ядра, такие как CPU, GPU, IO, DRAM, SRAM, кеш, ESD, управление питанием и интегрированные пассивные компоненты, могут свободно разделяться по всему корпусу, одновременно снижая общую высоту корпуса по оси Z.
Кроме того, в патенте подробно описываются шаги TSV и TOV, что предполагает, что сохранение малой высоты корпуса позволяет создавать переходные отверстия очень малого диаметра, причем TOV образуют ряды межсоединений размеров меньше, чем даже TSV. Также обсуждается влияние TSV на активные части кристалла, включая снижение производительности транзисторов, и уменьшенные шаги помогают смягчить это.
Зоны сохранения активного кристалла вокруг TSV
Включены РЧ-трансиверы и активные устройства на подложках, которые в настоящее время не используются в мобильных устройствах Apple, указывая на то, что все типы активных и пассивных компонентов, обнаруженных в продуктах Apple Watch, могут быть размещены в предлагаемом SiP.
Вид нижнего уровня SiP со стекированными гетерогенными кристаллами, соединенными TSV и TOV
Временная шкала
Корпуса с компонентами, соединенными по технологиям 2.5D и 3D, существуют в потребительских устройствах уже несколько лет, но большинство описанных выше методов еще не дебютировали в мобильных устройствах. Описанные шаги приведут к увеличению производственной сложности, и, вероятно, в результате пострадают стоимость и пропускная способность.
Из-за проблем с затратами и выходом годных изделий основным кандидатом на первое применение этих методов будет устройство с высокой маржой и низким объемом производства. В то время как iPhone является продуктом Apple с самой высокой маржой среди мобильных продуктов, это также самая крупносерийная категория с огромным первоначальным спросом на каждое поколение. iPad Pro является хорошим кандидатом из-за своего низкого объема производства и классификации как высокопроизводительное устройство. Включение частоты обновления 120 Гц — это то, что выиграет от увеличения пропускной способности памяти, в частности.
Фокус многих из этих патентов, по-видимому, сосредоточен на методах SiP, используемых во внутренностях Apple Watch. Apple Watch — это устройство с меньшим объемом производства, и оно выиграет, поскольку его внутренние компоненты чрезвычайно чувствительны к размеру корпуса, учитывая важность его форм-фактора и размера аккумулятора. Можно ожидать, что некоторые из описанных методов будут включены уже в следующем поколении Apple Watch, и более прогрессивно в будущих ревизиях.
Вчера мы сообщали об открытии Apple нового технологического центра в Орегоне и найме нескольких бывших старших инженеров Intel. Орегон является местом расположения объектов Intel в Хиллсборо, где находятся передовые 14-нм и 10-нм фабрики чипмейкера, а также экспертные знания в области проектирования ЦП для тепловых бюджетов настольных процессоров. Поиск открытых вакансий Apple показал, что существует несколько вакансий для инженеров-аппаратчиков с опытом работы в области компьютерной архитектуры и верификации кремния.
Кампус Intel Ronler Acres в Хиллсборо (Randy L. Rasmussen/The Oregonian)
Более глубокий анализ этих вакансий выявляет ключевые слова, указывающие на валидацию производительности в рабочих нагрузках, отличных от iOS, а также большой акцент на концепциях памяти, таких как контроллеры памяти, иерархия памяти и протоколы когерентности кэша. Акцент на подсистеме памяти важен, поскольку это одна из областей, где модели использования мобильных устройств и ПК отличаются из-за их профилей энергопотребления, а также ПК оснащены инструментами, которые могут сильно нагрузить систему памяти способами, обычно не встречающимися в рабочих нагрузках мобильных устройств.
Компьютерные системы также, как правило, имеют гораздо более высокую пропускную способность памяти из-за более широких шин памяти и более высоких тактовых частот памяти. Apple часто по слухам работает над MacBook на базе ARM, но такое устройство, вероятно, будет оснащено вариантом памяти LPDDR, используемой в мобильных устройствах Apple, а также всей линейкой MacBook от Apple.
Это означает, что у Apple уже есть необходимые разработки контроллеров памяти для взаимодействия с памятью LPDDR. Apple также хорошо знакома с 128-битными шинами памяти, используемыми в MacBook Pro с оперативной памятью LPDDR3, а также в предыдущих итерациях iPad с 128-битной шиной памяти.
Учитывая эту информацию, акцент на подсистеме памяти может указывать на более высокую целевую производительность системы памяти, с пропускной способностью памяти, более соответствующей настольным или рабочим станциям, где пропускная способность памяти может достигать сотен гигабайт в секунду.
Пожалуй, самым требовательным компонентом подсистемы памяти в пользовательском SoC, предназначенном для устройств macOS, является графический процессор. На стороне iOS Apple недавно перешла от лицензирования семейства графических процессоров PowerVR от Imagination Technologies к разработке собственных графических процессоров. Кроме того, центр проектирования графических процессоров Apple в Орландо прошел несколько этапов найма и в настоящее время также нанимает сотрудников, в том числе на должность архитектора платформ, нацеленную на создание семейства графических процессоров для нескольких платформ Apple.
Включение графического процессора в пользовательский SoC Apple, предназначенный для устройств macOS, потребует несколько гигабайт выделенной оперативной памяти с пропускной способностью памяти в сотни гигабайт для запуска современных игр на экранах Retina, которые имеются во многих продуктах Mac. В зависимости от размера кристалла, выделенного для ее решения, Apple потенциально может заменить чипы Intel со встроенной графикой в своих менее производительных продуктах MacBook или даже заменить дискретные графические процессоры, используемые в ее высокопроизводительных ноутбуках. Настольные машины, вероятно, потребуют отдельного дискретного графического процессора из-за ограничений по питанию и охлаждению, а также позволят общей наращивание размеров и сложности графических процессоров.
Чип A11 на материнской плате iPhone X (Источник: iFixit)
Для сравнения, ЦП и APU со встроенной графикой, используемые в современных ноутбуках и настольных системах, обычно имеют размер кристалла в диапазоне 200–400 мм², в то время как мобильные решения Apple обычно колеблются около 100 мм². Apple уже достигла производительности, сравнимой с ЦП Intel, используемыми в ноутбуках, благодаря своему новейшему чипу A11, и возможность масштабирования ее разработок по количеству ядер и энергопотреблению поможет ей конкурировать с ЦП с большим количеством ядер, используемыми в современных более производительных ноутбуках и настольных компьютерах.
Кроме того, Apple имеет хорошие возможности для перехода к более высокопроизводительным продуктам после демонстрации нескольких поколений пользовательских архитектур ЦП, включая собственные расширения набора инструкций для базового ISA ARMv8. Apple стояла у истоков усилий, которые в конечном итоге привели к появлению ARM в том виде, в котором мы знаем ее сегодня, и ее архитектурные амбиции были очевидны уже довольно давно. Вопрос о пользовательских ЦП Apple, предназначенных для ноутбуков и настольных систем, кажется скорее вопросом воли и воспринимаемого рыночного преимущества, чем вопросом возможностей.
Несмотря на позитивные результаты первого квартала 2018 года, Intel продолжает сталкиваться с проблемами на своих заводах, как с часто откладываемым 10-нм техпроцессом, так и с собственным производством модемов на 14-нм техпроцессе. Intel сообщила во время конференц-звонка по итогам отчетности, что массовое производство по 10-нм техпроцессу отложено до 2019 года, не уточнив конкретный период.
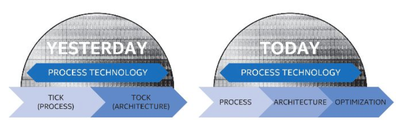
Дебют 10-нм техпроцесса Intel стал особенно болезненным моментом: грядущий Whiskey Lake станет пятым дебютом новой архитектуры на 14-нм техпроцессе. До 14-нм Intel придерживалась стратегии «tick-tock» для своих процессоров, которая предусматривала новую архитектуру на новом техпроцессе («tick») и более значительное архитектурное развитие на созревшем техпроцессе («tock»).
Мы впервые сообщили о кончине стратегии «tick-tock» в 2016 году. С тех пор ситуация для Intel только ухудшалась, так как 10-нм техпроцесс сталкивался с дальнейшими задержками. Чтобы понять масштаб этой задержки, стоит отметить, что первоначальные планы Intel предусматривали дебют 10-нм технологии в 2015 году. Существует несколько причин задержки, но генеральный директор Intel Брайан Крзанич объяснил, что некоторые функции 10-нм техпроцесса Intel требуют до пяти или шести этапов мультипаттернинга, в то время как другие конкурирующие заводы известны использованием до четырех этапов в 10-нм или 7-нм техпроцессах.
Это развитие имеет последствия для Intel, ее клиентов и конкурентов. Во-первых, Intel упустила технологическое преимущество, которое она когда-то имела над остальной полупроводниковой промышленностью. Хотя нельзя напрямую сравнивать размеры в названии техпроцесса между заводами, конкуренты, такие как TSMC, Samsung и Global Foundries, в основном достигли паритета с 10-нм техпроцессом Intel на своих 7-нм процессах, причем плотность транзисторов превосходит показатели собственных 10-нм процессоров Intel. Intel использовала метрику плотности транзисторов, чтобы противостоять маркетинговому ажиотажу, который создавали названия техпроцессов, но, похоже, потеряла и эти права хвастовства.
Что более важно, конкуренты Intel начинают массовое производство конкурирующих 7-нм техпроцессов. Хотя технологическое лидерство ранее было важно для Intel только как средство для создания превосходных продуктов, ее относительно недавнее открытие заводов для сторонних клиентов потеряло часть своего блеска в результате этих событий.
В ходе конференц-звонка Intel также признала, что ожидает уступить долю рынка конкуренту AMD, поскольку ее соперник добился недавнего успеха благодаря дебюту новых процессорных архитектур, таких как Zen, которые начали сокращать разрыв в производительности с собственными процессорами Intel. Ожидается, что AMD значительно увеличит свое присутствие в серверном сегменте благодаря недавним разработкам, а после выделения своего собственного завода в Global Foundries использует смесь бывшего внутреннего производства и TSMC. Ожидается, что AMD дебютирует потребительские продукты на 7-нм техпроцессе в 2019 году.
Влияние на Apple заключается в меньшем количестве обновлений процессоров для линейки продуктов Mac с незначительными улучшениями производительности между последующими поколениями. Apple известна тем, что отказалась от PowerPC из-за его стагнации и отставания в производительности от предложений Intel на базе x86, и теперь ситуация, похоже, повторяется с упорными слухами о том, что Apple может использовать свои собственные процессоры для линейки продуктов Mac.
Продукты Apple iPhone и iPad также затронуты, поскольку растущая зависимость компании от модемов Intel сдерживается проблемами Intel с производством модемов в больших объемах на собственном 14-нм техпроцессе.
Модемы Intel, продукт приобретения Infineon, как и предполагалось изначально, до недавнего времени производились на техпроцессах TSMC. XMM 7560, гигабитный модем Intel с поддержкой CDMA, будет производиться на собственном 14-нм техпроцессе и, как широко ожидается, будет представлен в следующих мобильных продуктах Apple.
Intel также стремится выйти на рынок RF и аналоговых решений и недавно раскрыла детали своего 22FFL техпроцесса, сочетающего 22-нм, 14-нм и 10-нм продуктовые линейки, ориентированные на более дешевые и энергоэффективные решения, а также на аналоговые и RF компоненты. Однако, примечательно отсутствие в этом сообщении анонса каких-либо выигранных контрактов на дизайн.
RF-трансиверы Intel, такие как SMARTi 7 RF transceiver, который сопряжен с модемом XMM 7560, были бы отличным кандидатом для такого техпроцесса. Отсутствие такого анонса предполагает, что он по-прежнему производится на заводе с устоявшейся историей производства RF/аналоговых компонентов — скорее всего, на TSMC.
Наконец, Intel может столкнуться с еще одним раскрытием уязвимостей процессоров: Anandtech сообщает со ссылкой на журнал c’t, что в сообществе специалистов по безопасности в настоящее время исследуются новые уязвимости, и Intel опубликовала собственное заявление по безопасности данных, по-видимому, в преддверии этого раскрытия. Масштаб эксплойтов, по-видимому, сопоставим с оригинальными уязвимостями Spectre и Meltdown, и Intel уже готовит патчи для вновь выявленных эксплойтов, согласно c’t.
Ожидается, что эти уязвимости затронут ARM и AMD, как и по крайней мере один из оригинальных эксплойтов Spectre и Meltdown, но Intel, возможно, подвергается наибольшему вниманию из-за своего высокого положения на рынке.
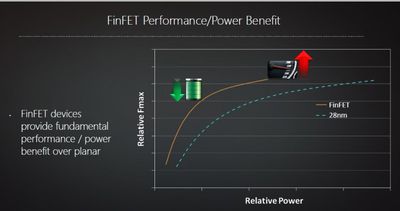
В ходе своего последнего отчета о прибылях за первый квартал TSMC объявила, что ее технологический процесс FinFET с нормами 7 нанометров введен в массовое производство (HVM), что означает, что мы можем увидеть потребительские устройства с этим процессом уже во второй половине этого года.
Предыдущие отчеты указывали на то, что TSMC ожидает получить исключительную ответственность за производство предстоящего чипа Apple A12 и его вариантов, которые, как ожидается, дебютируют в новых продуктах iPhone и iPad начиная с этой осени. Ожидается, что 7-нанометровый процесс (обозначаемый как CLN7FF, 7FF или просто N7) обеспечит примерно 40-процентное преимущество по энергопотреблению и площади по сравнению с 10-нанометровым процессом FinFET от TSMC, используемым в процессорах Apple A11.
Кроме того, как сообщает EETimes, TSMC предоставила информацию о своей дорожной карте технологий как для своих кремниевых процессов, так и для технологий корпусирования устройств. Считается, что TSMC отвоевала эксклюзивное производство процессоров Apple у двойного поставщика Samsung благодаря своим достижениям в области корпусирования на уровне пластины (wafer-level packaging). (На тот момент также в основном осталось незамеченным представление TSMC конденсаторов с боковым расположением, прикрепленных непосредственно к подложке.)
Опираясь на лидерство в области корпусирования, достигнутое благодаря предложениям по корпусированию InFO, TSMC теперь анонсировала шесть новых типов корпусирования, ориентированных на различные устройства и приложения.
Техника InFO получает четыре «родственника». Info-MS, для подложки памяти, упаковывает SoC и HBM на подложке размером с одну ретикулу (1x) с уровнем перераспределения 2 x 2 микрона и будет сертифицирована в сентябре.
InFO-oS имеет обратную сторону RDL (redistribution layer) с более точным соответствием DRAM и готова сейчас. Вариант с многоуровневым стекированием под названием MUST помещает один или два чипа поверх другого, большего чипа, соединенного через интерпозер у основания стека.
Наконец, InFO-AIP означает «антенна в корпусе» (antenna-in-package), обеспечивая на 10% меньший форм-фактор и на 40% более высокий коэффициент усиления. Он ориентирован на такие конструкции, как фронтальные модули для 5G-модемов.
Но это еще не все. TSMC представила два совершенно новых варианта корпусирования. Корпус «пластина на пластине» (wafer-on-wafer, WoW) напрямую соединяет до трех кристаллов. Он был выпущен на прошлой неделе, но пользователям необходимо убедиться, что их EDA-потоки поддерживают технику соединения. Поддержка EMI будет добавлена в июне.
Наконец, foundry примерно описала нечто, что она назвала «системы на интегрированных чипах» (system-on-integrated-chips, SoICs), используя соединения менее 10 микрон для связи двух кристаллов, но детали этой техники, которая будет выпущена в следующем году, пока еще скудны. Она ориентирована на приложения от мобильных устройств до высокопроизводительных вычислений и может соединять кристаллы, изготовленные по разным техпроцессам, что предполагает, что это может быть форма «система в корпусе» (system-in-package).
Объявление этих технологий корпусирования важно, поскольку они позволят реализовать различные структуры корпусов и соединений для SoC Apple, причем непосредственное преимущество заключается в новых интерфейсах для памяти в корпусе. В то время как InFO предлагает преимущества по высоте, производительности и тепловым характеристикам для Apple, им все еще необходимо соединяться с ОЗУ, расположенной поверх процессора приложений, с помощью проводных соединений в конфигурации «корпус на корпусе» (package-on-package).
Этот интерфейс создает тепловые проблемы и ограничивает ширину и скорость шины памяти из-за типа соединений. Индустрия интегральных схем видела немало усилий в области новых технологий памяти, таких как High Bandwidth Memory (HBM), но эта технология в основном ограничивалась графическими процессорами, предназначенными для научных, исследовательских и энтузиастских применений, из-за высокой стоимости и низкого выхода годных материалов кремниевых интерпозеров, которые обеспечивают соединения от чипа к памяти. Тот факт, что TSMC представила вариант InFO, напрямую нацеленный на это решение, предвещает его более широкое внедрение в индустрии в различных продуктах.
Процесс InFO-oS представляет гораздо больший краткосрочный интерес для производителей мобильных устройств, таких как Apple, где ширина шины памяти будет значительно ниже, но пропускная способность на вывод будет намного выше, как видно на примере LPDDR4. Согласно отчету TSMC, часть «oS» в этой технологии относится к «on-substrate» (на подложке), где будет происходить разделение кристаллов.
Это, казалось бы, позволяет реализовать 2.5D-решение, где кристалл памяти располагается рядом с кристаллом процессора, а не подвешивается над ним через компаунд, как в исходном корпусировании InFO-WLP, что обеспечивает более высокую плотность соединений. Однако сохранение слоя перераспределения означает, что компаунд все равно должен присутствовать, поэтому более полное техническое раскрытие информации может помочь устранить некоторую двусмысленность этого названия. Хотя это и устранило бы стекирование кристаллов, это увеличило бы общую площадь упакованного решения, что по-прежнему было бы проблемой для компактного мобильного корпуса.
Варианты TSMC InFO
Хотя Apple в конечном итоге может перейти на решение HBM, которое обеспечивает гораздо большую пропускную способность памяти при более низком энергопотреблении, анонс wafer-on-wafer (WoW) является реальным шагом к истинным 3D-интегрированным схемам, где в конечном итоге кристаллы будут уложены непосредственно друг на друга и соединены через переходные отверстия, расположенные непосредственно в кристалле ИС.
Инновация для TSMC здесь будет заключаться именно в том, как она упаковывает эти кристаллы вместе, как выглядят интерфейсы, а также какие типы слоев перераспределения (RDL) они предлагают. Хотя InFO-AIP напрямую не применим к линейке процессоров Apple, это также важное развитие, поскольку радиочастотные (RF) фронтальные модули стоят на пороге еще одного порядка сложности с их внедрением гораздо более широких полос частот, необходимых для стандартов 5G.
Помимо 7-нанометрового процесса, TSMC также поделилась своими планами относительно последующих процессов foundry — 7 нм+ и 5 нм. 7 нм+ будет первым процессом TSMC, использующим экстремальную ультрафиолетовую (EUV) литографию, которая упростит процесс маскирования, устранив необходимость в многократном шаблонировании во многих областях для формирования более мелких структур.
За 7 нм+ последует 5 нм, который войдет в рисковое производство к концу следующего года, если текущие сроки сохранятся, что означает, что массовое производство будет осуществляться примерно в 2020 году, хотя, вероятно, слишком поздно для запуска продукта осенью 2020 года, даже при самых оптимистичных сроках. Хотя EUV долгожданна и решит многие проблемы в отрасли, она приносит с собой целый ряд собственных проблем и не приведет к огромным скачкам производительности в последующих процессах, а также не обеспечит более плавные переходы между процессами, поскольку 5 нм уже представляет свои собственные проблемы с EUV.
Процесс обеспечивает на 35% большую скорость или потребляет на 65% меньше энергии и обеспечивает 3-кратное увеличение плотности маршрутизированных вентилей. Напротив, процесс N7+ с EUV обеспечит только на 20% большую плотность, на 10% меньшее энергопотребление и, по-видимому, никакого увеличения скорости — и эти усовершенствования требуют использования новых стандартных ячеек.
Тем не менее, вышеупомянутые новости обнадеживают, поскольку Apple должна иметь возможность пользоваться преимуществами нового технологического процесса как минимум два из следующих трех лет. Это даст толчок по мере замедления развития архитектуры ее процессоров, а появление новых методов корпусирования позволит Apple преодолеть ограничения по пропускной способности и тепловыделению способами, которые раньше были просто невозможны.
TSMC также дала надежду на будущее, обрисовав картину за пределами 5 нм в общих чертах с планами по внедрению новых транзисторных топологий, таких как кремниевые нанопроволоки, и переходу от кремния в качестве основного полупроводникового материала к материалам, которые в конечном итоге предлагают более высокую подвижность носителей (электронов и дырок).
TSMC также подробно описала способы улучшения проводимости и снижения паразитных явлений, связанных с соединениями, присутствующими в кремниевом кристалле. В конечном итоге эти соединения часто определяют, насколько быстро транзисторы могут переключаться из-за эффективной нагрузки на линии, и это проблема на всех этапах — от кристалла до корпуса и до печатной платы. TSMC, по-видимому, усердно ищет различные решения для своих клиентов по двум из этих направлений, а ее упаковочные решения все больше переносят эти компоненты печатной платы непосредственно в корпус устройства для борьбы с третьим элементом.
Поскольку завтра наступает день запуска iPhone X от Apple, нетерпеливые пользователи смогут наслаждаться временем автономной работы, обычно доступным для более крупных моделей Apple Plus, в телефоне, размеры которого больше похожи на модели не-Плюс. Причина этого прорыва заключается не в разработке плотности энергии, а скорее в меньшей печатной плате (PCB) внутри iPhone X, согласно отчету KGI Securities за февраль.
Эта меньшая печатная плата стала возможной благодаря технологии, называемой печатными платами, подобными субстрату, или SLP. Изображения из отчета показывают печатную плату с большим количеством слоев, чем традиционная печатная плата iPhone, благодаря выделенным печатным платам для процессора приложений и радиочастотной сигнальной цепи, объединенных через интерпозер, создавая стековую конструкцию почти в два раза больше, чем у обычных печатных плат iPhone.
Однако это далеко не вся история. Хотя новая компоновка печатной платы может предложить некоторую дополнительную гибкость в размещении компонентов, важно помнить, что обратная сторона платы от A11 в iPhone 8 не пуста. Там тоже много компонентов — чип NFC, драйверы дисплея, комбинированные чипы Wi-Fi и микросхемы управления питанием часто находили свое место непосредственно напротив основного процессора приложений.
Ведь у 4,7-дюймовых iPhone и их 5,5-дюймовых «плюсовых» собратьев печатные платы примерно одинакового размера, что напрямую влияет на емкость аккумулятора в меньших телефонах. В этом кроется настоящая проблема при попытке улучшить время автономной работы в этих компактных форм-факторах.
Обратная сторона печатной платы iPhone 8 Plus, любезно предоставлено iFixit
Сокращение занимаемой площади компонентов
Чтобы сделать печатную плату iPhone X меньше, Apple пришлось найти способ уменьшить общую площадь, занимаемую компонентами на печатных платах. При беглом взгляде на приведенную выше печатную плату видно, что плата плотно заполнена интегральными схемами и пассивными компонентами. Естественный первый вопрос: можно ли просто исключить компоненты?
Отличным кандидатом для упрощения могла бы стать радиочастотная цепь. Действительно, в предыдущих iPhone для разных операторов по всему миру существовало до четырех вариантов, поскольку они оснащались переключателями, фильтрами и усилителями, ориентированными на конкретные диапазоны, необходимые для этих регионально-специфичных операторов. Количество вариантов за эти годы сократилось до текущих двух, и они были сведены к одной модели с поддержкой сетей CDMA и одной без нее.
Поддерживая меньше диапазонов на модель в большем количестве моделей, Apple могла бы уменьшить общий размер радиочастотной цепи и сэкономить место на плате. Взгляд на страницу технических характеристик iPhone X покажет, что Apple этого не сделала, поскольку она поддерживает те же самые диапазоны, что и модели iPhone 8, в двух версиях.
Таким образом, нам приходится искать за пределами радиочастотной цепи для сокращения количества компонентов. Другой способ уменьшить размер компонентов — заставить поставщиков интегральных схем сократить свои собственные корпуса. Лучшим примером этого может служить оригинальный MacBook Air, где Intel предоставила меньший корпус для процессора, чтобы помочь Apple достичь тогдашнего крошечного форм-фактора.
Если бы поставщик сделал это, он, безусловно, включил бы это и в iPhone 8 или 8 Plus, поэтому можно было бы ожидать какого-либо давления со стороны стоимости или объема на компонент, препятствующий его более широкому распространению. Примером может служить корпус, включающий интерпозер, который представляет собой дорогие соединительные структуры, позволяющие размещать несколько устройств с высокой плотностью выводов в одном корпусе. Это та же самая концепция, которая, как говорят, используется для соединения радиочастотных и основных цифровых плат внутри iPhone X.
Концепция размещения нескольких компонентов в одном корпусе не нова. Большинство чипов серии A от Apple имеют внутри стеклянную память DRAM, и Apple приложила усилия для уменьшения размера корпуса с помощью InFO packaging от TSMC. Apple Watch использует еще более интегрированный подход с их решением System-in-Package (SiP), включающим различные активные и пассивные компоненты в одном корпусе с крышкой. Это общее направление развития мобильных устройств.
Решение о том, размещать ли компоненты на многослойной печатной плате или переносить уровень интеграции на корпус или даже на кристалл, — это тщательное взвешивание стоимости, экономии места и влияния на производительность. Перемещение компонентов на корпус обычно улучшает производительность, поскольку сигнальные пути становятся короче и требуют меньше энергии для работы, но за счет более сложных решений для корпуса и подложки.
Размещение схем на кристалле обеспечивает максимальную производительность, но увеличивает размер кристалла, что может повлиять на выход годных компонентов и, в конечном счете, на стоимость. Ключ ко многим из этих концепций — понимание того, что сама по себе SLP на самом деле не помогает.
Печатные платы, подобные субстрату
Когда производители компонентов ссылаются на новую технологию печатных плат как на печатные платы, подобные субстрату, они имеют в виду плотность соединений, обеспечиваемую субстратами, используемыми в корпусах интегральных схем. Снижая размеры элементов до 15 микрон, эти новые типы печатных плат помогают достичь плотности соединений, сравнимой с корпусами интегральных схем. Это очень полезно для высокоплотной маршрутизации, такой как шины памяти или PCI. Размещение большего количества маршрутов на одном слое, наряду с меньшими сквозными элементами, также аналогичными субстратам корпуса, в конечном итоге поможет использовать меньше слоев для маршрутизации печатной платы.
Печатная плата, подобная субстрату, с микросквозными отверстиями
Однако память iPhone X уже интегрирована в корпус, и у нее нет широких высокоскоростных интерфейсов данных, которые можно найти на традиционной настольной платформе. Таким образом, это, вероятно, не является основным новшеством, напрямую приносящим пользу iPhone X. Интерпозер между платами, вероятно, помогает в этом.
Интерпозер позволит цифровой и радиочастотной платам быть спроектированными отдельно перед их соединением интерпозером, расположенным между ними. Этот тип многоэтапного подхода является обычным для печатных плат, поскольку они часто начинаются с непроводящих сердечников, которые затем наращиваются последовательными слоями металла и диэлектрика, позволяя производителю добавлять маленькие сквозные отверстия слой за слоем для сложной печатной платы. Интерпозер расширяет эту концепцию, интегрируя еще более плотную шаг соединения, обычно предназначенный для корпусов устройств, и значительно увеличивая стоимость.
Границы цепей на печатной плате iPhone 8 Plus
Этот отдельный подход к печатным платам поможет Apple достичь лучшей изоляции между своими цифровыми и радиочастотными секциями. Действительно, при ближайшем рассмотрении печатной платы iPhone видны пунктирные линии, разделяющие типы цепей. На приведенном выше изображении показаны разделенные аудио- и радиочастотные секции на печатной плате iPhone 8 Plus.
Разделение этих компонентов важно, поскольку помехи от соседних компонентов могут привести, например, к снижению динамического диапазона в аналоговых и радиочастотных цепях или к нарушению целостности сигнала в цифровых цепях. В потребительском устройстве также вызывают беспокойство излучаемые сигналы. Apple предприняла шаги по увеличению самосовместимости и соответствия стандартам, когда она запатентовала, а затем внедрила и улучшила напыленные покрытия для чипов, используемых в ее мобильных устройствах.
Все эти шаги помогают Apple располагать компоненты ближе друг к другу и дают больше свободы в выборе места их расположения относительно друг друга. Однако пространство на плате по-прежнему в значительной степени занято. Агрессивные усилия могут вернуть до 10 процентов пространства на плате, но этого недостаточно, чтобы значительно сократить размер печатной платы. Инженерам Apple нужно использовать не только измерения X и Y.
3D Техники
Чтобы добиться реального прогресса в пространстве, необходимом для размещения всех компонентов в iPhone, также необходимо использовать высоту печатных плат. 3D и 2.5D методы производства интегральных схем, такие как стекирование кристаллов, сквозные кремниевые отверстия, интерпозеры и другие методы, получили широкое освещение в последние годы для упаковки устройств, но они также в некоторой степени применимы к печатным платам. Производители печатных плат годами встраивают простые пассивные компоненты, такие как резисторы, конденсаторы и индукторы, в печатные платы.
Эти элементы изначально были неотъемлемой частью процесса, будь то резистивные пленки, печатные намотанные дорожки или использование диэлектрика печатной платы в качестве основы для конденсатора, образованного между слоями. Встроенные физические компоненты сейчас набирают популярность, и производители даже планируют встраивать активные компоненты в ближайшем будущем.
Встроенные и сформированные компоненты на уровне пластин
Хотя это прошло несколько незамеченным, Apple уже применяет эту технику в своих процессорах серии A. Несколько лет назад в утечках упакованных деталей начали появляться любопытные пустоты на нижней стороне, где ожидалась обычная матрица соединений. Эти пустоты, вероятно, являются местами для пассивных фильтрующих компонентов, которые размещаются внутри корпуса.
Чип Apple A11 со встроенными компонентами
Это достигает двух целей. Во-первых, оно уменьшает площадь платы, необходимую для установки всех компонентов. Во-вторых, оно часто несет преимущество в производительности, поскольку близость к металлу внутри устройства является одним из ключевых факторов производительности активных устройств, таких как это.
Конденсаторы и индукторы, используемые для фильтрации и байпаса питания процессора приложений, служат для предотвращения падения напряжения при изменяющихся требованиях к току, а также для обеспечения байпасного пути к земле для высокочастотного шума. Размещение его как можно ближе к устройству уменьшает нежелательные паразитные явления, снижающие эффективность этих компонентов.
Пассивные фильтрующие компоненты для A11 на печатной плате iPhone 8 Plus
Расширяя эту концепцию на печатные платы, Apple может использовать любое дополнительное пространство внутри печатной платы для размещения этих компонентов. Изучение обратной стороны печатной платы iPhone 8 Plus показывает, что на задней стороне печатной платы за A11 расположено множество пассивных компонентов.
Чем больше этих компонентов можно встроить в стековую конструкцию платы, тем более эффективным по площади может быть дизайн. В крайнем случае, печатная плата будет иметь эти компоненты нетронутыми, а интерпозер (или, возможно, несколько, чередующихся со связующим материалом для соответствия платам) будет иметь вырез в этой области, чтобы цифровые и радиочастотные платы могли быть ламинированы вместе. Эта концепция сама по себе представляет технические трудности, и следует ожидать постепенного внедрения, а не значительного сдвига для встроенных компонентов.
Что должно стать ясно в будущем, так это то, что внутренние компоненты стековых конструкций печатных плат могут оказаться столь же интересными, как и их поверхности, и рентгеновские снимки кристаллов компонентов, которые мы ожидаем увидеть. Возможно, мы получим представление о некоторых из этих концепций, как только начнутся разборки.
После того как ряд устройств iPhone 8 и 8 Plus оказался в руках пользователей, набор для сетевого бенчмаркинга Ookla Speedtest.net смог собрать данные о том, как новейшие iPhone работают по сравнению с моделями предыдущего поколения, и поделился деталями с PCMag.
На основе данных, собранных Ookla, улучшения для большинства пользователей составляют около 10 процентов, но пользователи в Австралии благодаря структуре своей сети могут ожидать увеличения скорости до 25 процентов. Эти пользователи смогут использовать полную пропускную способность агрегации операторов связи 80 МГц в телефоне благодаря использованию Telestra соответствующих диапазонов.
Скорость загрузки на iPhone 8 по сравнению с предыдущими поколениями
Помимо сравнения скорости с предыдущими поколениями iPhone, PCMag также сравнивает сотовую архитектуру iPhone 8 с конкурирующими телефонами, такими как Galaxy S8.
В iPhone 8 отсутствует один из компонентов, необходимых для гигабитного LTE, или LTE категории 16, в США. Модем Qualcomm X16 может работать в категории 16, как мы видели на Galaxy S8 и Moto Z2 Force. Телефон поддерживает кодирование 256QAM и агрегацию 4x до 80 МГц спектра, но не антенны 4×4 MIMO, которые улучшили бы как скорость, так и силу сигнала. Теоретически это сделало бы его телефоном со скоростью 800 Мбит/с, также известным как LTE категории 15.
Отсутствие антенн 4×4 MIMO — это то, на что мы уже обращали внимание на MacRumors во вторник. В то время как модемы Qualcomm и Intel в новых iPhone, вероятно, более энергоэффективны, фронт-энд и бэк-энд, поддерживающие их, в основном неизменны по структуре по сравнению с моделями iPhone 7.
В статье далее отмечается, что это может привести к потере покрытия из-за недостаточной разнородности приемника по сравнению с другими телефонами, что подтверждается тестом в нью-йоркском метро.
Отсутствие 4×4 MIMO, вероятно, является причиной того, что iPhone по-прежнему уступает Galaxy S8 в восстановлении связи после «мертвых зон», что является известной проблемой iPhone. Мы взяли iPhone 8 и Galaxy S8 в метро Нью-Йорка, где они теряли и восстанавливали покрытие T-Mobile. Galaxy S8 восстанавливал связь быстрее в 8 из 11 тестов, и когда это происходило, он был в среднем на 16 секунд быстрее iPhone в восстановлении сигнала LTE; когда iPhone выигрывал, он делал это в среднем на 5 секунд быстрее.
Пользователям, ищущим разблокированный iPhone, вероятно, все же стоит выбрать модель Verizon или Sprint с модемом Qualcomm. Хотя он демонстрирует более высокие пиковые скорости, чем модемы Intel, согласно агрегированным пользовательским данным, неясно, превосходит ли он по покрытию, что потребует более глубокого тестирования.
Наконец, пользователи, ожидающие iPhone X, должны ожидать той же дихотомии моделей и производительности, учитывая, что страница технических характеристик iPhone X совпадает с моделями iPhone 8 по количеству поддерживаемых моделей и диапазонов. Форм-фактор, вероятно, не окажет никакого влияния на антенные структуры, которое существенно повлияет на пользователей.
В дальнейшем внедрение структуры антенн 4×4 MIMO станет одним из крупнейших достижений, которое Apple может сделать для скорости и надежности покрытия будущих iPhone.
Apple выпустила iPhone 8 и iPhone 8 Plus в пятницу, 22 сентября, и разбор устройств был начат в течение нескольких часов благодаря iFixit и TechInsights. Компании получили разные модели для разбора: в модели iFixit использовался модем Qualcomm, а в модели TechInsights — модем Intel, что продолжает тенденцию Apple использовать модемы Intel в телефонах, не требующих поддержки сетей CDMA.
В каждом iPhone были установлены новые чипы модемов от соответствующих поставщиков: в CDMA-телефоне использовался новый гигабитный модем Qualcomm X16, а в модели на базе Intel — аналогично новый модем XMM 7480. Каждая модель также включала обновление трансиверного модуля, соответствующего модему, но существенные изменения в цепочке радиочастотного сигнала на этом в основном и заканчивались.
Сравнение функций Qualcomm X16 и X12
Помимо более высоких пиковых скоростей по сравнению с предшественниками, оба этих модема предлагают другие потенциальные преимущества. Сравнение страниц сетевой совместимости iPhone 7 и iPhone 8 показывает, что поддерживаемые диапазоны в основном остались прежними, что отражается в незначительных изменениях модулей усилителей мощности (PAM) в радиочастотной цепи.
Помимо пиковых теоретических скоростей гигабитного уровня, модем X16 предлагает несколько других усовершенствований, включая агрегацию до 4 несущих с общей полосой пропускания до 80 МГц по сравнению с 60 МГц в MDM9645M (X12), питающем iPhone 7. Модем Qualcomm X16 также поддерживает новый спектр LTE 600 МГц от T-Mobile US, диапазон 71. Apple не указывает поддержку диапазона 71 для модели, продаваемой для использования с T-Mobile, что означает либо отсутствие поддержки диапазона 71 модемом Intel для соответствующей модели T-Mobile, либо решение Apple не включать поддержку в структуру антенны/PAM телефона.
Ключевые особенности Intel XMM 7480
Intel XMM 7480, напротив, имеет максимальную теоретическую пиковую скорость всего 600 Мбит/с, и хотя он также поддерживает агрегацию до 4 несущих, две из этих полос ограничены 10 МГц, что ограничивает общую полосу пропускания до 60 МГц. Intel увеличила поддержку диапазонов до более чем 33, заявляя о лидирующем в отрасли показателе, но, вероятно, существуют и другие недостатки по сравнению с модемом Qualcomm, которые были приняты из-за желания Apple обеспечить разнообразие поставщиков этого компонента.
Тем не менее, очевидно, что оба этих модема являются усовершенствованием по сравнению с их предшественниками, однако Apple не уделила времени обсуждению расширенных возможностей сотовой связи для каких-либо своих телефонов на мероприятии для СМИ в начале этого месяца. Вместо этого, основной причиной перехода на эти новые модемы, вероятно, является энергопотребление.
Разбор показал, что Apple уменьшила размеры батарей в линейке iPhone 8, сохранив при этом прежние заявления о времени автономной работы. В iPhone X ситуация с пространством будет еще хуже, учитывая заявления Apple об аналогичном времени автономной работы iPhone 8 Plus при форм-факторе не Plus. Хотя есть и другие улучшения, вероятно, скрытые за кулисами, кажется очевидным, что Apple хотела повысить эффективность своих сотовых радиомодулей.
Это также будет область, на которую стоит обратить внимание в iPhone X, поскольку сотовая радиочастотная цепь является одним из крупнейших потребителей пространства в телефоне. Согласно странице спецификаций, iPhone X будет поддерживать те же диапазоны в двух моделях, что и его собраты серии 8, поэтому пространство, возможно, придется искать в другом месте.
Усовершенствования в энергоэффективности модемов, вероятно, исходят из двух разных источников для Qualcomm и Intel. Согласно Qualcomm, X16 построен на 14-нм техпроцессе FinFET, который, вероятно, имеет несколько преимуществ перед 28-нм радиочастотным процессом, использовавшимся в ее предыдущих модемах.
Intel, с другой стороны, заявляет о снижении энергопотребления до 15 % по сравнению с модемом предыдущего поколения, что может быть отчасти связано с новым встроенным отслеживателем огибающей для регулирования напряжения, который снижает энергопотребление и нагрев. Хотя неясно, на каком техпроцессе построен модем Intel, вероятно, это все еще 28-нм процесс от TSMC, поскольку Intel продолжает работать над технологиями, унаследованными от приобретения Infineon. Тем не менее, будущие iPhone будут хорошо подготовлены к включению более широкой полосы пропускания и более разнообразных сетевых возможностей в будущем, даже если используемые в них модемы останутся прежними.
В среду на форуме Open Innovation Platform Ecosystem Forum в Санта-Кларе производитель чипов TSMC представил обновленную информацию (через EE Times) о прогрессе в разработке своих будущих технологических процессов, несколько из которых могут быть использованы для грядущих чипов Apple. Примечательно, что первый 7-нанометровый техпроцесс компании уже прошел несколько стадий финальной доводки (tape-outs) и ожидает достижения полного объема производства в 2018 году.
10-нанометровый техпроцесс TSMC, впервые примененный в чипе Apple A10X для iPad Pro, а затем в A11, столкнулся с проблемами (платная ссылка), такими как низкий выход годных чипов и производительность ниже первоначальных ожиданий. TSMC надеется изменить свою судьбу с новым 7-нм техпроцессом, который, учитывая текущие сроки, подойдет для преемника чипа A11.
Помимо 7-нм техпроцесса, TSMC также поделилась информацией о последующей его модификации под названием N7+. Этот вариант, использующий долгожданную технологию экстремальной ультрафиолетовой литографии (EUV), обещает на 20% большую плотность размещения компонентов, примерно на 10% более высокую скорость или на 15% меньшее энергопотребление при прочих равных условиях.
Хотя EUV сталкивалась с задержками более десяти лет, похоже, что она наконец-то выходит на финишную прямую, и предполагаемое начало массового производства в 2019 году позволит Apple снова обновить свои чиповые техпроцессы в последующие годы. Ранее Apple ежегодно обновляла техпроцессы для всех моделей iPhone, начиная с перехода на 3GS, прежде чем была вынуждена использовать 16-нм техпроцесс TSMC в течение двух лет подряд для чипов A9 и A10. В дальнейшем этот ежегодный цикл снова под вопросом, поскольку производители чипов сталкиваются с реалиями физики и минимальными размерами транзисторной геометрии.
TSMC также представила несколько энергоэффективных техпроцессов с низким уровнем утечек, подходящих для других пользовательских разработок Apple, таких как линейка беспроводных чипов, например, W1 и его преемник W2. TSMC нацелена на выпуск 22-нм техпроцесса с ультранизкими утечками в следующем году, который подходит для аналоговых и радиочастотных разработок, таких как модемы или Wi-Fi чипы.
В конечном итоге это поможет Apple еще больше снизить энергопотребление Apple Watch и наушников, оснащенных беспроводными чипами серии W. Вероятно, этот техпроцесс будет использоваться и Qualcomm для своей линейки модемных продуктов. Производственные процессы для W1 и W2 в настоящее время публично не известны, но весьма вероятно, что один из радиочастотных техпроцессов TSMC используется для производства чипов Apple.
Наконец, TSMC объявила об изменении своего процесса интегрированной корпусировки с вентильным выводом (InFO), предназначенного для интеграции памяти с высокой пропускной способностью (HBM) в сборку, под названием InFO-MS. HBM вызывает большой интерес для приложений, где требуется очень высокая устойчивая пропускная способность памяти, например, для потребительских видеокарт.
HBM и аналогичные стандарты, такие как Wide I/O, обещают не только увеличить пропускную способность памяти, но и снизить энергопотребление при заданной пропускной способности, что делает их подходящей эволюцией для мобильных SoC-дизайнов. Этот тип интерфейса памяти еще не появился в мобильных устройствах, хотя его появление ожидается в ближайшем будущем. Несмотря на достижения в области мобильной памяти, она по-прежнему уступает настольным и ноутбукам по общей пропускной способности, что может быть важно для некоторых задач, таких как рендеринг графики.
В недавней утечке информации от Apple использовалось дерево устройств, предоставленное Стивеном Трафтон-Смитом и содержащее информацию, специфичную для iPhone X, для получения данных о кодовых именах ЦП, наличии OLED-дисплея и многом другом. В этой информации также содержались конкретные сведения об архитектуре новых ядер ЦП Apple, получивших название «Mistral» и «Monsoon». Из этого мы знаем, что A11 содержит четыре ядра Mistral и два ядра Monsoon, и стоит технически рассмотреть, что Apple может делать с этим новым чипом.
В то время как два ядра Monsoon являются явным продолжением двух больших ядер «Hurricane» в A10, ядра Mistral удваивают количество малых ядер по сравнению с двумя ядрами «Zephyr» в A10.
Слайд с мероприятия в сентябре 2016 года о двух ядрах Zephyr в A10
Аннотированные снимки кристалла в конечном итоге показали, что малые ядра Zephyr были встроены в более крупные ядра Hurricane, используя их географическое расположение путем совместного использования структуры памяти с ядрами Hurricane.
Аннотированное фото кристалла A10 от Chipworks/TechInsights, показывающее малые ядра Zephyr, встроенные в большие ядра Hurricane (справа)
Ядра Mistral, по-видимому, являются отходом от вышеуказанной схемы, по крайней мере, в том смысле, что их количество удвоилось. В дереве устройств также есть конкретные ссылки на иерархию памяти, что предполагает наличие независимых кэшей L2, а значит, ядра Mistral могут быть более независимыми, чем их предшественники в A10.
Эта независимость подчеркивается тем фактом, что ядра Mistral имеют общий идентификатор кластера («cluster-id»), в то время как ядра Monsoon имеют свой собственный, отличный идентификатор кластера. Немедленно были проведены сравнения с гетерогенной схемой процессорных ядер big.LITTLE от ARM в A10, и это, похоже, движется дальше по этому пути с различными режимами работы для каждого кластера ядер. Однако совместное использование ресурсов в A10 приносило определенную выгоду, а именно: экономию места на кристалле и энергопотребление. Становление ядер более независимыми больше похоже на традиционный подход big.LITTLE, который также влечет за собой больший накладной расход.
Конечно, все это может быть упрощением. В конце концов, мы знаем, что каждое из этих ядер ЦП доступно независимо, что означает, что ничего из раскрытого до сих пор не указывает на то, что активное ядро или кластер Mistral или Monsoon исключает активность другого типа ЦП, открывая двери для сценариев смешанных процессоров. Apple могла решить приложить усилия, будь то в оборудовании, компиляторах или в обоих случаях, чтобы разделить инструкции по сложности и в конечном итоге направить их на ядро, которое будет выполнять их наиболее эффективно.
Решение проблем таким образом стало бы еще одним примером в длинном списке попыток Apple улучшить эффективность выполнения инструкций за счет усовершенствований микроархитектуры.
Любые архитектурные изменения в конечном итоге приводят к улучшениям в той или иной форме. Если Apple вносит изменение, которое включает удвоение количества маломощных ядер, кажется неизбежным, что она тратит больше места на кристалле, особенно если у них есть собственные структуры кэша от L2 и ниже.
Тем не менее, как отметил редактор AnandTech Иэн Катресс, ARM начала разрешать настраиваемые размеры кэшей для своих предложений ядер. В данном конкретном случае несуществующий кэш L2 является допустимой конфигурацией, что означает, что увеличение места на кристалле может быть не таким большим, как кажется на первый взгляд, при увеличении количества малых ядер.
Важно помнить, что Apple не связана этими конвенциями ARM, но они являются показателем того, куда движется индустрия. Также важно помнить, что общий кэш L3 всегда находится над всеми ядрами, а также над графическим процессором и процессором обработки изображений. В конечном итоге эти архитектурные изменения, вероятно, сводятся к увеличению производительности на ватт, увеличению количества инструкций за цикл или, возможно, к обоим показателям. Учитывая, что малые задачи, для которых может активироваться ядро Mistral, вероятно, не раскрывают параллелизма, необходимого для всех четырех ядер, кажется весьма вероятным наличие интересных сценариев использования с A11 SoC от Apple.
Чтобы дать контекст смешанному ансамблю ядер A11, современные центральные процессоры агрессивно управляют производительностью и энергопотреблением, динамически изменяя тактовые частоты, напряжения процессора и даже отключая целые ядра ЦП путем управления тактовыми частотами и питанием этих ядер. В программном обеспечении существует множество ссылок на все эти концепции, в дополнение к нескольким ссылкам на динамическое управление ЦП и ядрами, а также на количество инструкций за такт, пороговые значения пропускной способности памяти, пороговые значения энергопотребления и даже гистерезис, чтобы ядра не запускались и не останавливались при изменении профиля производительности. Нет сомнений, что многие из этих свойств существовали и в A10, но тот факт, что Apple увеличивает количество малых ядер, показывает, что Apple считает, что здесь есть большая выгода.
Ссылка на «bcm4357» в дереве устройств iPhone X
Однако помимо ЦП и OLED-дисплея содержится больше деталей. Программное обеспечение явно указывает на BCM4357 от Broadcom как на Wi-Fi модуль. Это любопытно, потому что BCM4357 на самом деле является очень старым Wi-Fi чипсетом. Вероятно, Apple отбросила последние 0 из BCM43570, что соответствует профилю 802.11ac iPhone 7 (и, следовательно, не является улучшением). Однако у Broadcom есть чип BCM4375 на горизонте, который поддерживает грядущий стандарт 802.11ax. Если только на презентации не будут конкретно освещены скорости Wi-Fi, мы можем не получить немедленного разъяснения здесь, учитывая, что Wi-Fi модуль часто встраивается в более крупный модуль, часто интегратором компонентов Murata.
Переходя к дисплею, свойство пиковой яркости в нитах, к сожалению, похоже, ссылается на значение полной шкалы, а не на фактическое десятичное значение в нитах. Это могло бы дать представление о том, стремится ли Apple следовать каким-либо существующим на рынке HDR-стандартам, которые часто требуют пиковой яркости более 1000 нит.
В области аудио ссылка на CS35L26 подтверждает еще одну победу Cirrus Logic для верхних и нижних динамиков, а CS42L75 — это недокументированный аудиокодек. Наконец, для чистой мелочи, есть ссылка на свойство ‘sochot’, которое любопытно ссылается на идентификатор чипа A6X. Оно также содержит ссылку ‘N41’ в разделе базовой станции, которая относится к кодовому названию iPhone 5, который впервые представил LTE для семейств iPhone. Однако это могут быть просто ссылки на старые устройства, когда функции или свойства были впервые представлены.
Apple, несомненно, раскроет некоторые детали о новом чипе A11 и других внутренних улучшениях новых iPhone на своем мероприятии, которое состоится всего через несколько часов, но другая информация будет ждать, пока фирмы, занимающиеся разборкой устройств, не получат их и не смогут более внимательно изучить, что находится внутри.
На прошедшем в среду мероприятии Apple представила два новых процессора — A10 Fusion для iPhone 7 и 7 Plus, а также S2 для Apple Watch Series 2. Хотя Apple лишь кратко упомянула S2 во время презентации, значительное время было посвящено A10 Fusion. Суффикс «Fusion» указывает на гетерогенную архитектуру A10, которая включает два высокопроизводительных ядра и два более мелких, более энергоэффективных ядра.
Apple также представила еще один очень важный самостоятельный чип в своих новых AirPods — чип W1. В совокупности это представляет собой огромный объем инженерной работы, проделанной Apple за последний год, а A10 является самым значительным усовершенствованием в линейке систем-на-чипе (SoC) Apple со времен перехода компании на 64-битную архитектуру.
Apple в самом начале представила основные технические изменения A10, заявив о четырехъядерном процессоре с 3,3 миллиарда транзисторов. Хотя Apple никогда не раскрывала количество транзисторов для A9, оно, скорее всего, находилось где-то между 2 миллиардами у A8 и 3,3 миллиарда у нового A10. Количество транзисторов значительно меньше 3 миллиардов кажется вероятным для A9; в противном случае этим стоило бы гордиться отдельно.
3,3 миллиарда транзисторов у A10 более чем на 50% больше, чем у A8, и такое значительное увеличение, вероятно, в основном связано с добавлением двух новых, хотя и небольших, процессорных ядер, а также с значительно улучшенным процессором обработки изображений (ISP). Apple также сообщила, что GPU по-прежнему имеет шестикластерную конструкцию, в то время как результаты тестов предполагают, что размеры кэша L1 и L2 остались неизменными.
Учитывая, что технологический процесс, как ожидается, не изменится по сравнению с A9, произведенным по 16-нм FinFET процессу TSMC, весьма вероятно, что мы увидим больший размер кристалла по сравнению с предшественником. Однако также вероятно, что Apple смогла оптимизировать размещение и размеры на более зрелом процессе, без дополнительной сложности производства двойной конструкции на конкурирующем 14-нм FinFET процессе Samsung.
Утечки изображений материнской платы также предполагают больший размер корпуса устройства, чем у Apple A9, хотя неясно, оказывает ли новый процессор упаковки InFO какое-либо влияние на размер корпуса устройства.
Apple также сообщила, что пиковая производительность A10 может быть до 40% выше, чем у A9, использовавшегося в предыдущем поколении. Тактовая частота 2,33 ГГц, показанная в тестах, примерно на 25% быстрее, чем 1,85 ГГц у A9, что означает, что Apple достигла еще 25% прироста производительности за счет архитектурных усовершенствований.
Увеличение тактовой частоты на 25% является значительным, учитывая, что технологический процесс, вероятно, не изменился, что означает, что увеличение было, скорее всего, обусловлено лучшей теплопроизводительностью упаковки InFO. Это также, вероятно, возможно благодаря гетерогенной архитектуре Apple, которая теперь включает пару высокоскоростных ядер наряду с парой низкоскоростных, энергоэффективных ядер.
Увеличение тактовой частоты Apple, вероятно, больше, чем просто увеличение напряжения для ускорения работы ядер. Внедряя пару низкоскоростных ядер, Apple открыла совершенно новый спектр опций динамического масштабирования напряжения и частоты (DVFS) для полного отключения ядер или их подчастей. Apple разработала собственный контроллер производительности для управления рабочими нагрузками между ядрами, и мы знаем из отраслевых источников, что Apple осуществляет совместное использование кэшей, чтобы кэшам не приходилось постоянно считывать содержимое друг друга для готовности к переключению, чтобы избежать задержек в получении текущих данных при переключении.
Эта концепция может показаться знакомой, поскольку ARM представила ее еще в 2011 году с дизайном Cortex-A15 «Eagle» в 2012 году под названием «big.LITTLE». Схема ARM big.LITTLE также включает контроллер производительности и механизмы согласованности кэшей, но она должна была быть разработана с учетом управления производительностью ОС Linux, в то время как Apple может перенастраивать iOS по мере необходимости для любых программных интерфейсов к контроллеру производительности. Со временем мы можем узнать больше о том, какие кэши используются совместно, а какие обновляются с помощью какого-либо механизма согласованности.
Увеличение тактовой частоты до 2,33 ГГц приближает Apple к тактовой частоте конкурентов от производителей SoC, таких как Qualcomm и Samsung, и Apple также могла внести некоторые изменения в транзисторы для достижения этих скоростей. Увеличивая напряжение и выбирая транзисторы с более высокой утечкой статического тока (неизбежная потеря мощности), Apple может достичь этих более высоких тактовых частот. Команда разработчиков чипов Apple также может создавать архитектурные решения с более высоким энергопотреблением в целом, будь то большее количество транзисторов, избыточные затраты на управление или большая активность переключения за счет другого метода реализации логики.
Вывод заключается в том, что теперь допустимо идти на эти компромиссы, поскольку они лучше справляются с тепловыми последствиями и им не приходится иметь дело со статическим энергопотреблением всех этих изменений, когда схема не используется активно, поскольку они могут просто отключить ее и переключиться на низкоэнергетическое ядро.
Два небольших ядра A10 от Apple вызвали не меньший интерес, чем их более крупные аналоги, с большим количеством спекуляций относительно того, являются ли они также разработкой Apple или вариантом стандартного низкопроизводительного ядра от ARM, такого как Cortex-A53. После стольких лет полностью заказных разработок справедливо спросить, почему Apple выбрала бы готовое решение для своего низкопроизводительного ЦП, но прецеденты для этого, безусловно, есть.
По всем признакам, Apple Watch первого поколения используют дизайн процессора Cortex-A7. Сравнение с Apple Watch интересно, поскольку Series 2 была просто увеличена до двухъядерной конструкции, на 50% более быстрой, чем оригинал. Тот же вопрос о заказной против стандартной конструкции здесь актуален, и вполне возможно, что двухъядерный процессор в S2 — это тот же двухъядерный процессор, который используется в качестве низкопроизводительного варианта в A10.
Основной вопрос, связанный с этим архитектурным сдвигом, заключается в том, почему именно сейчас Apple решила перейти на гетерогенную архитектуру. Одна из возможностей заключается в том, что основные разработки ядер Apple были настолько оптимизированы, что осталось мало возможностей для улучшения, и эти улучшения имели бы серьезную убывающую доходность. Повышение тактовой частоты — это простой способ получить больше производительности, но связанные с этим тепловые и энергетические затраты, возможно, были движущей силой разделения.
Размер кристалла также не безграничен, и до тех пор, пока были возможности для увеличения процессоров, Apple могла выбрать этот путь. Улучшенные функции ISP также могли быть веской причиной для увеличения кэша L3 SRAM с 4 МБ до 8 МБ, что также влияет на размер кристалла. В дальнейшем важно помнить, что тактовая частота процессоров также не будет безграничной, например, высокопроизводительные настольные процессоры остаются в пределах от 3 ГГц до 4 ГГц последние десять лет.
Apple завершила свой технический обзор, рассказав о графической мощности A10. К счастью, Фил Шиллер упомянул, что это шестикластерная конструкция, так что мы знаем, что она соответствует количеству кластеров в A9. Заявления Apple о производительности также предполагают, что GPU A10 может быть до 50% быстрее, чем GPU A9, потребляя при этом только 2/3 энергии.
Мы также знаем, что Apple использовала тот же технологический процесс для A10, что и для A9. Поскольку после анонса серии GPU 7XT от Imagination Technologies, использовавшейся в A9, от ImgTec был представлен только один новый тип высокопроизводительного GPU, который был просто добавлен для улучшений производительности компьютерного зрения и вычислений в существующую линейку 7XT.
Само по себе снижение энергопотребления исключает увеличение тактовой частоты Apple для обеспечения этих заявлений о производительности, поэтому мы, вероятно, рассматриваем некоторые значительные изменения, включающие неанонсированный GPU, разработанный Apple GPU или какой-либо другой важный архитектурный сдвиг, о котором мы не знаем. Возможно, Apple может заявить о некотором приросте за счет улучшений в Metal, но до 50% ускорения кажутся довольно высоким заявлением для этого.
Заявления Apple о повышении производительности исторически склонны находить отражение в тестах, поэтому это будет областью особого интереса, когда GPU будет полностью протестирован и рассмотрен под микроскопом.
Представление AirPods от Apple также было важным моментом, поскольку они оснащены новым чипом беспроводной связи W1 от Apple. В своем объявлении Фил Шиллер особо подчеркнул, что это первый беспроводной чип Apple, предполагая, что их будет больше. Мы ждали несколько лет с тех пор, как Apple впервые наняла нескольких инженеров по радиочастотам из Broadcom, и этот небольшой чип Bluetooth может стать ступенькой к тому, чтобы Apple предоставляла свои собственные радиочастотные компоненты, такие как чип Wi-Fi или даже сотовый базовый модем в будущих устройствах.
Однако выйти на этот рынок и стать конкурентоспособным в общем сегменте очень сложно, как, например, видно по собственным предложениям Intel в области LTE, вероятно, представленным в новом iPhone. Вместо того чтобы создаваться с нуля, эти чипы являются продуктом приобретения Infineon компанией Intel и производятся по техпроцессу TSMC, а не собственному техпроцессу Intel. Потенциальные выгоды от заказных беспроводных чипов также менее очевидны, чем от полностью заказных процессорных решений, используемых в SoC, поэтому это не обязательно означает, что амбиции Apple простираются так далеко.
Мы, вероятно, узнаем гораздо больше в ближайшие недели, когда начнутся разборки устройств, будут проведены исчерпывающие тесты и начнут появляться более детальные аналитические данные от таких фирм, как Chipworks. Оттуда мы получим лучшее представление о конкретных методах и приемах, которые Apple использовала для повышения производительности чипов, и, возможно, получим лучшее представление о том, что будет дальше.
На прошлой неделе MacRumors осветил фотографии того, что, по-видимому, являются передней и задней сторонами плат iPhone 7, и с тех пор мы смогли изучить эти платы и сравнить их с платами предыдущих поколений iPhone.
Сравнение плат с существующими предложениями компонентов и информацией предполагает, что Apple действительно отказалась от Qualcomm в качестве поставщика модемов базовой частоты и перешла на Intel для следующего поколения iPhone. Это не исключает того, что у Apple могут быть другие версии плат iPhone 7 или 7 Plus с модемом Qualcomm, например, международная модель с другими вариантами диапазонов LTE, как слухи.
Утечка платы iPhone 7 с указанием расположения модема Intel
На изображении выше представлена ранее опубликованная и аннотированная передняя сторона платы с предполагаемым расположением модема базовой частоты Intel. Рисунок контактных площадок для этого компонента заметно отличается от рисунка контактных площадок Qualcomm MDM9635, как показано в каталоге запчастей iFixit. Рисунок контактных площадок этого загадочного компонента также соответствует размерам указанным на сайте Intel для аналогичных решений базовых модемов, как и предполагаемое решение XMM 7360.
Трансивер радиочастотного диапазона Intel SMARTi 5, который сопровождает модем в референсном решении Intel, по-видимому, отсутствует на плате iPhone 7, судя по размерам корпуса, специфичным для трансивера. Всегда возможно, что указанные размеры относятся к решению, отличному от того, которое использует Apple, будь то заказное или неанонсированное, но похоже, что Qualcomm по-прежнему может быть поставщиком трансивера радиочастотного диапазона.
Хотя точного совпадения контактов между платами нет, размер корпуса и общее количество контактных площадок на обратной стороне соответствуют чипам управления питанием и модемам WTR3925 и Qualcomm, которые были на платах iPhone 6S и 6s Plus. Рисунки контактных площадок также имеют смещенные ряды контактов, что исторически было отличительной чертой рисунков контактных площадок Qualcomm на предыдущих iPhone.
Сравнение нижней задней части плат iPhone 6s (слева) и iPhone 7 (справа)
В области, где, вероятно, располагается трансивер в нижней задней части, мы увидели довольно много изменений: металлизация, разделяющая радиочастотный контур и компоненты аудио/аккумулятора, изменила ориентацию с горизонтальной на вертикальную. В результате площадь, выделенная для аудиоусилителей и зарядного устройства аккумулятора, увеличилась. С предполагаемым удалением разъема для наушников, похоже, что Apple готова убрать один усилитель, хотя это и не очевидно из утечки фотографии. С инверсией подключения дисплея и потенциальным внедрением емкостной кнопки «домой» есть веские причины, по которым эта область могла увеличиться.
Сравнение рисунков контактных площадок A9 (слева) и A10 (справа)
Наконец, глядя на A10, мы замечаем пустой ряд контактных площадок рядом со всеми четырьмя краями рисунка контактных площадок. На самом деле это не новость для A10, так как рисунок контактных площадок A9 также имел это. Это также довольно распространено в больших чипах, таких как настольные процессоры, где входы и выходы рядом с краем устройства отделены от основного питания и сигналов устройства. Это привело к увеличению корпуса A9, несмотря на небольшое уменьшение кристалла по сравнению с A8.
Учитывая, что A10, вероятно, будет использовать тот же техпроцесс 16 нм FinFET, что и A9, или его оптимизированный вариант, вполне возможно, что мы увидим увеличение размера кристалла без большого скачка в количестве транзисторов. Что касается упаковки InFO от TSMC, то пока неясно, приведет ли это к увеличению размеров упаковки для устройств Apple.
Охват платы A10 также включает четыре прямоугольных блока отсутствующих контактов. Это на самом деле могут быть места для небольших компонентов непосредственно под корпусом устройства. Как правило, производительность некоторых компонентов чипа, используемых для фильтрации питания, лучше всего достигается за счет максимально близкого расположения к контактам устройства, и они обычно размещаются непосредственно на обратной стороне печатной платы, соединенные вертикальными металлическими соединениями через плату, называемыми переходными отверстиями, под чипами с большим количеством цифровой коммутационной функциональности. Для большинства мобильных устройств такого пространства нет, но это может быть одним из объяснений этих участков отсутствующих контактов.
До официального анонса iPhone 7 осталось всего несколько недель, поэтому мы можем увидеть утечки плат с установленными чипами и другими компонентами, что даст нам больше информации об изменениях в компонентах нового устройства. Однако полные сведения вряд ли появятся до тех пор, пока эксперты по разборке не получат новый iPhone и не смогут изучить компоненты и даже рассмотреть их под микроскопом.
В прошлом году MacRumorsписал о потенциальных причинах возвращения Apple к работе с единственным партнером по производству чипов серии Apple A с чипом A10, после того как версии чипа Apple A9 производились как Samsung, так и TSMC.
С тех пор TSMC подтвердила в ходе выступлений на конференц-связи, что изменения в упаковке чипов привели к 20-процентному улучшению скорости и толщины корпуса, а также 10-процентному улучшению тепловых характеристик. Это имеет ряд последствий для будущей производительности устройств и выбора литейных партнеров для Apple.
Во-первых, важно понять, почему InFO-WLP (Integrated Fan-Out Wafer-Level Packing) является столь значимым достижением для мобильных процессоров Apple. Обычно такие большие чипы, как центральные процессоры или мобильные системы на кристалле (SoC), монтируются с использованием методов «флип-чип», когда массив входов и выходов крепится к подложке корпуса с помощью паяных выводов, что в конечном итоге позволяет подключить его к печатной плате (PCB) для интеграции в устройство.
С самого начала это является компромиссом, поскольку предпочтительнее было бы подключать кремниевый кристалл непосредственно к печатной плате, чтобы минимизировать высоту и уменьшить длину межсоединений между компонентами. Ряд технических ограничений в таких областях, как шаг межсоединений, технологичность производства платы и повреждения из-за коробления платы, обычно препятствуют такому прямому подключению.
Указанная проблема ранее обходилась для компонентов с меньшим количеством выводов с помощью аналогичной концепции под названием Fan-In Wafer-Level Packing, где меньшие кристаллы позволяют маршрутизировать свои входы и выходы в области, примерно равной площади самого кристалла. TSMC является одной из многих компаний, начинающих внедрять эту концепцию для устройств с большим количеством выводов таким образом, чтобы обеспечить высокий объем производства, приемлемые уровни выхода годных и приемлемую стоимость.
Слайд из презентации TSMC 2014 года о достижениях в области InFO-WLP
При таком методе традиционная подложка становится ненужной, поскольку кремниевая пластина выполняет эту функцию с одним или несколькими логическими кристаллами. Уменьшенная высота этого метода и более тонкий слой перемаршрутизации (RDL) для переподключения выводов кристалла к печатной плате означают, что все межсоединения становятся короче, что напрямую способствует снижению энергопотребления и улучшению тепловых характеристик. Транзисторы, управляющие выходами на этом устройстве, теперь управляют меньшей длиной металла, что означает, что они могут экономить энергию. Экономия энергии также означает улучшение тепловых характеристик, но более прямое соединение с печатной платой означает меньшее тепловое сопротивление к печатной плате, которая может отводить тепло от устройства.
Обещанные улучшения производительности, безусловно, значительны. Улучшение производительности на 20 процентов примерно эквивалентно улучшению, ожидаемому между последовательными технологическими процессами (например, переход от 14 нм к 10 нм). Поскольку и TSMC, и Samsung предлагают только усовершенствованные версии своих 16-нм и 14-нм FinFET процессов, это означает, что общий прирост производительности может быть сопоставим с тем же улучшением, которое наблюдалось от чипа A8 к A9, но обусловлен улучшением упаковки, а не новым процессом.
Конечно, каждое поколение не может наслаждаться одинаковым улучшением, но повышенная энергоэффективность критически важна для мобильных устройств, чтобы им разрешалось достигать более высоких пиковых пределов в течение коротких периодов времени. В своем выступлении на презентации устройств семейства iPhone 6 Apple подробно рассказала о том, как она приложила значительные усилия, чтобы процессор A8 не снижал производительность, в отличие от A7. Это было и остается общеотраслевой проблемой, поскольку производители мобильных SoC соревновались за предоставление самых производительных чипов. Используя новую упаковку от TSMC, Apple получает большую выгоду по этому показателю и свободу переходить в режим более высокого энергопотребления на короткие периоды.
Пустая материнская плата iPhone 7 с местом для чипа A10
Долгосрочное преимущество этой технологии заключается в обеспечении гораздо более быстрых интерфейсов основной памяти к логическому кристаллу, в основном за счет расширения интерфейса. Современные корпуса мобильных SoC используют методы PoP (package-on-package), которые соединяют кристаллы памяти с основным процессором с помощью крошечных проводов, что неэффективно с точки зрения теплоотвода и не идеально для производительности. Используя упаковку на уровне пластин, эти недостатки могут быть уменьшены для основной памяти, одновременно увеличивая количество соединений и данных, которые могут быть переданы за определенное время.
В долгосрочной перспективе этот шаг, вероятно, станет экономией для Apple, поскольку он устраняет подложку корпуса. Однако совместное проектирование кристалла устройства и корпуса устройства объясняет, почему несколько партнеров технически невозможны для таких усилий. Такие компании, как TSMC, также годами работали над тем, чтобы сделать это реальностью, поскольку преимущества были давно понятны.
На данный момент нельзя отрицать техническую компетентность и возможности Apple в области проектирования чипов. Компания разработала множество чипов для рынка в чрезвычайно сжатые сроки с полностью индивидуальным дизайном, который соперничает с разработками Intel по соотношению производительности на ватт. Apple опередила своих конкурентов на рынке с 64-битным ARM-дизайном более чем на год и разработала два нестандартных кристалла A9 за то время, которое ее конкуренты разработали один.
Учитывая стремление Apple повышать производительность своих кремниевых продуктов и достижения TSMC в области упаковки, вполне логично, что TSMC смогла получить единоличное право на заказы чипов Apple, по крайней мере, в этом поколении. В перспективе технология упаковки InFO-WLP является значительным достижением не только для TSMC и Apple, но и для всей полупроводниковой промышленности.
Одной из ключевых задач для Apple при разработке Apple Watch было обеспечение приемлемого времени автономной работы устройства, несмотря на энергоемкие компоненты, такие как основной процессор и дисплей.
С выпуском watchOS 3 на конференции WWDC в июне Apple продемонстрировала возможность одновременной работы нескольких приложений Apple Watch с обновлением в фоновом режиме, признав, что первоначальный подход к управлению питанием и другими системными ресурсами был консервативным, но реальный опыт показал, что устройство может справляться с более требовательными задачами.
Помимо улучшений программного обеспечения, будущие поколения Apple Watch должны стать более эффективными на аппаратном уровне, а одним из основных направлений для улучшения являются новые версии чипа S1, который служит «мозгом» устройства. Учитывая это, мы детально изучили, что может предложить полупроводниковая технология в будущем для устройств с ограниченным временем автономной работы, таких как Apple Watch.
По мере того как транзисторы достигают физических пределов своего размера в современных полупроводниковых процессах, становится все труднее и, следовательно, дороже делать их меньше. Помимо того, что стоимость одного транзистора перестает снижаться, становится также сложнее контролировать потери мощности или утечку. Новые геометрии транзисторов, такие как непланарные «3D» FinFET, становятся популярными для решения проблемы утечки, но поскольку носимые устройства, такие как Apple Watch, начали вызывать интерес потребителей, достигнутые в этих полупроводниковых процессах преимущества просто недостаточны.
Для носимого устройства, такого как Apple Watch, контроль энергопотребления в режиме ожидания имеет решающее значение для сохранения конкурентоспособного общего времени автономной работы. Потребность в сверхнизком энергопотреблении и более дешевых кремниевых процессах, которые также конкурентоспособны по производительности, привела к использованию транзисторов, изготовленных с использованием более традиционных методов литографии с более высокими затратами на подложку.
Ведущей технологией этого типа является полностью обедненный кремний на изоляторе, или FD-SOI. Технология FD-SOI отличается от традиционных «массивных» транзисторов (используемых в устройствах Apple до и включая A8) двумя основными способами. Первое улучшение заключается в том, что сверхтонкий канал поверх изолирующего корпуса устраняет необходимость легирования канала дополнительными носителями заряда (положительными или отрицательными), устраняя источник вариативности устройств, который может снизить производительность. Второе улучшение заключается в том, что изолирующий корпус и другие характеристики значительно снижают ток утечки.
Дополнительные преимущества этого процесса заключаются в возможности динамически управлять производительностью переключения транзисторов путем смещения корпуса транзистора. Это также можно делать в традиционных массивных полупроводниках, но ценой снижения производительности утечки. В случае транзисторов FD-SOI это означает, что производительность транзисторов может модулироваться в реальном времени.
Современные чипы уже используют различные формы динамического масштабирования частоты и напряжения (DVFS), но благодаря использованию прямого смещения корпуса возможности управления транзисторами FD-SOI еще шире. Транзисторы могут динамически управляться для более быстрого переключения путем модуляции количества напряжения, которое должно быть подано на затвор устройства, чтобы эффективно сформировать канал для работы транзистора.
Это динамическое управление между прямым и обратным смещением корпуса означает, что транзисторы могут работать при чрезвычайно низких напряжениях, близких к пороговому значению. Работая всего при 0,5 В, потребление энергии может быть значительно снижено, поскольку мощность устройства часто напрямую коррелирует с квадратом (или кубом) приложенного напряжения.
Эта технология важна для носимых устройств, поскольку основной системный чип (SoC) может в значительной степени влиять на энергопотребление устройства, особенно когда большая часть использования приходится на режим ожидания, как показано на примере устройства на базе Android справа. Обзоры показали, что неправильный SoC может полностью испортить производительность батареи умных часов. Другим важным фактором в расходе батареи умных часов является экран — компонент, в котором Apple в значительной степени зависит от своих поставщиков, чтобы получить продукт с приемлемой производительностью.
Быстрый оборот в дизайне групп процессоров Apple, в дополнение к одновременному выпуску SoC A9 на конкурирующих процессах FinFET, свидетельствует о том, что Apple обладает техническими возможностями для внедрения дополнительного процесса проектирования в свою продуктовую линейку. Фактически, мы знаем, что оригинальный SoC S1, используемый в первом поколении Apple Watch, был изготовлен по 28-нм LP-процессу Samsung, в отличие от лидирующего 20-нм процесса, который был бы доступен в то время.
Не будет необоснованным предположить, что Apple может сделать своего рода боковой шаг и принять 28-нм FD-SOI-процесс Samsung, который доступен сейчас. В дальнейшем существует возможность использования 22-нм FD-SOI-процесса, и эта технология, несомненно, будет продолжать развиваться, если рынок подтвердит спрос с течением времени.
FD-SOI также имеет огромный потенциал для аналоговых и радиочастотных (RF) приложений благодаря своим низким характеристикам утечки. Не будет удивительно, если поставщики RF-фронтенда, такие как Qualcomm, начнут использовать FD-SOI для своих модемов и многодиапазонных усилителей, и если наем Apple инженеров с RF-экспертизой когда-либо принесет свои плоды, это будет подходящий вариант для более кастомных компонентов непосредственно от Apple. В любом случае, не удивляйтесь, если аналитические обзоры следующих Apple Watch преподнесут несколько сюрпризов, когда фирмы по разборке устройств возьмут в руки свои микроскопы.
Samsung снова готов начать поставлять Apple чипы флэш-памяти NAND в 2017 году, завершив пятилетний перерыв, начавшийся с момента выпуска iPhone 5 в 2012 году, сообщает ETNews. Причиной прекращения первоначальных отношений с поставщиком называется нежелание Samsung соответствовать требованиям Apple по экранированию от электромагнитных помех (EMI) путем изменения упаковки или нанесения специальных покрытий на сами пакеты памяти.
Это новое заявление появилось на фоне предыдущего сообщения также от ETNews, в котором говорилось, что Apple стремится индивидуально экранировать больше компонентов внутри своих устройств для повышения производительности и соответствия требованиям по EMI.
В предыдущей статье утверждалось, что причиной этого изменения стало использование множества различных систем, таких как 3D Touch, а также наличие различных высокоскоростных интерфейсов, которые могут способствовать возникновению ЭМП и подвергаться их воздействию. Индивидуальное экранирование также позволило бы Apple отказаться от дискретных металлических экранирующих компонентов, что в конечном итоге позволило бы сэкономить место на плате и выделить больше пространства для других компонентов внутри устройств.
В новом сообщении отмечается, что использование Samsung корпусировки типа «шариковая сборка» (BGA) ставит его в невыгодное положение по сравнению с конкурирующими продуктами, использующими контакты типа «сетка контактов» (LGA), которые позволяют пакету быть вровень с печатной платой.
Тип LGA (слева) по сравнению с типом BGA (справа)
Похоже, что существующие технологии экранирования от ЭМП методом напыления Samsung были недостаточны для удовлетворения требований Apple к производительности, учитывая пробелы в экранировании, создаваемые приподнятыми контактами BGA. Появление новых, более дешевых методов распыления ультратонких слоев металлического экранирования, по-видимому, является одним из событий, изменивших динамику этих отношений, как и опасения Samsung по поводу ослабления рынка флэш-памяти.
Samsung остается лидером в решениях типа NAND, предлагая на рынке свои 3D V-NAND памяти с плотностью до 256 Гбит. Хотя это развитие, скорее всего, повлияет на память, используемую в продуктах Apple iPhone и iPad, существует также возможность для Samsung появиться во всей линейке компьютеров Mac, которые стали сильно зависеть от флэш-хранилищ. Наряду с недавними новостями о том, что Samsung будет поставлять Apple OLED-панели для будущих iPhone, похоже, что Samsung по-прежнему играет важную роль в качестве поставщика для устройств Apple.
В развитие своей прошлогодней информации о крупном заказе AMD октября, издание WCCFtechподтвердило по нескольким источникам, что этим заказчиком является Apple. Этот новый заказ следует за использованием Apple GPU серии AMD 200/300 в топовых моделях 27-дюймовых iMac Retina и 15-дюймовых MacBook Pro Retina, и является большим успехом для производителя чипов, чья доля на рынке графических процессоров неуклонно снижалась в течение последних нескольких лет.
Заказы включают два семейства графических процессоров: Polaris 10 и Polaris 11. Первый имеет кодовое название «Ellesmere» и, как полагают, подходит по энергопотреблению для обновления iMac. Polaris 11 имеет кодовое название «Baffin» и, как полагают, подходит по энергопотреблению для обновления Retina MacBook Pro.
Хотя Apple ограничивает использование дискретных графических чипов топовыми моделями своих MacBook Pro и iMac, существуют подходящие чипы для всех, кроме самых компактных форм-факторов ноутбуков Apple, если компания решит использовать дискретную графику в более широком ассортименте моделей.
Как мы отмечали ранее, переход на новую линейку графических процессоров Polaris станет значительным шагом вперед по производительности по сравнению с предыдущими 28-нм GPU. Анонсированные AMD на Computex, низкопотребляющие GPU AMD будут созданы на 14-нм процессе Global Foundries. Благодаря соглашению между несколькими производителями, этот процесс эквивалентен второму поколению 14-нм FinFET процесса Samsung, который является преемником процесса, использованного для чипов A9 и A9X в новейших iPhone и iPad.
Ожидается, что производительность этих новых графических чипов от AMD будет вдвое выше, чем у их предшественников, при одинаковом потреблении энергии. Это стало возможным благодаря значительному уменьшению размера и повышению производительности при переходе от 28-нм техпроцесса, впервые примененного для графических процессоров в 2011 году, к новым 16/14-нм FinFET процессам. Это, безусловно, будет приветствоваться линейкой Mac из-за возросших графических требований дисплеев Retina высокого разрешения, используемых в компьютерах iMac и MacBook Pro. Разумно ожидать, что Apple выделит примерно такой же бюджет мощности, как и в текущих моделях, что означает, что удвоенная производительность может быть видна пользователям в некоторых случаях.
По предварительным данным, чипы должны быть готовы к поставке в потребительских продуктах к началу учебного года. Не является чем-то неслыханным, что Apple получает приоритет на новые разработки чипов, хотя WWDC было бы наиболее логичным временем для дебюта этих новых Mac. Будущее Mac Pro менее определено, хотя в этом году безусловно появятся подходящие высокопроизводительные чипы от AMD, произведенные по 16-нм процессу TSMC.
В своем последнем годовом отчете 10-K (PDF), поданном в прошлом месяце, Intel подтвердила конец своей долгожданной стратегии «тик-так» по выводу новых микропроцессоров на рынок. Изначально Intel представила этот производственный цикл миру в 2006 году с запуском микроархитектуры «Core», чередуя «тики» уменьшения технологических процессов изготовления чипов с «токами» новых архитектур.
За последние десять лет Intel последовательно выпускала новые семейства процессоров на основе этого цикла «тик-так» почти ежегодно, начиная с 65-нм производственного узла и до недавнего времени. Цикл выпуска «тик-так» позволил Intel восстановить доминирование как на потребительском, так и на корпоративном рынке ЦП и давал OEM-производителям, таким как Apple, регулярный цикл обновлений для ежегодных продуктовых обновлений. Но поскольку обновления чипов в последние поколения стали растягиваться более чем на год, это начало сказываться на циклах выпуска продукции Apple.
В связи с трудностями в поддержании цикла «тик-так» Intel объявила, что выпуск Kaby Lake в этом году в качестве третьего представителя 14-нм семейства после Broadwell и Skylake ознаменует официальный конец стратегии «тик-так». Вместо этого Intel перейдет к новой модели «Процесс-Архитектура-Оптимизация» для текущего 14-нм узла и 10-нм узла.
В рамках наших научно-исследовательских работ мы планируем регулярно представлять новую микроархитектуру Intel Core для настольных компьютеров, ноутбуков (включая устройства Ultrabook и системы 2-в-1) и процессоров Intel Xeon. Мы ожидаем продлить срок использования наших 14-нм и наших 10-нм технологических процессов следующего поколения, далее оптимизируя наши продукты и технологические процессы, одновременно соблюдая ежегодный рыночный ритм выпуска продукции.
Это развитие событий не является неожиданным, поскольку производители полупроводников сталкиваются со все большими трудностями в создании более мелких технологических узлов, так как изготовление более мелких транзисторов становится все более дорогим и сложным. Транзисторы стремительно приближаются к физическим пределам традиционных полупроводниковых геометрий, и знаменитый закон Мура относительно плотности транзисторов был официально признан недействительным.
Intel, несомненно, перешла на эту новую модель выпуска в попытке вернуться к регулярному ритму выпуска продукции и платформ, поскольку компания борется с технологическими проблемами вывода новых производственных узлов на массовое производство. Как было отмечено в нашем руководстве для покупателей Mac, многие Mac от Apple долгое время не обновлялись с момента начала их отслеживания, хотя Apple еще не обновила свою линейку Mac до доступной микроархитектуры Skylake. Некоторая неопределенность в отношении продуктов сохранится, поскольку запуск микроархитектуры Intel Kaby Lake был недавно задержан на вторую половину 2016 года после того, как Skylake пострадал от аналогичных задержек в прошлом году.
Крупные поставщики графических процессоров AMD и Nvidia в этом году представят новые продукты GPU с использованием 14-нм FinFET процессоров от Global Foundries и 16-нм FinFET Plus от TSMC соответственно, что позволит добиться значительного улучшения графической производительности.
«Polaris» от AMD и «Pascal» от Nvidia, обе архитектуры используют новейшие FinFET кремниевые процессы и станут первым изменением техпроцесса GPU с момента дебюта 28-нм GPU в 2011 году. И AMD, и Nvidia пропустили промежуточный 20-нм узел, что продлило типичный цикл выпуска потребительских графических процессоров.
В то время как TSMC традиционно предлагала несколько вариантов техпроцесса в рамках одного узла, включая один специально разработанный для высокопроизводительных приложений, таких как GPU, компания обнаружила, что традиционные планарные геометрии ее 20-нм узла давали фирме меньше возможностей для дифференциации с обычным набором настроек, делая его плохим кандидатом для энергоемких GPU.
В заявлении, опубликованном ранее в этом году, AMD утверждала, что новые 14-нм GPU Polaris предложат более чем вдвое большую производительность на ватт по сравнению с их 28-нм предшественниками. Эта новость также подтвердила использование AMD 14-нм FinFET процесса от Global Foundries, а не 16-нм процесса TSMC, который будет использовать Nvidia. Хотя AMD подтвердила использование TSMC для своих более мощных продуктов, любые продукты, разработанные на базе этого техпроцесса, предназначались бы только для Mac Pro, поскольку Apple традиционно использовала мобильные GPU для своих ноутбуков и линеек продуктов iMac.
Новые техпроцессы FinFET обещают большой скачок производительности для архитектуры Polaris от AMD
Ожидается, что запуск этих новых GPU состоится примерно летом. Хотя Nvidia представила свою новую массивную графическую карту Tesla P100 на этой неделе, один слух предполагает более широкий запуск линейки GeForce Pascal компании примерно во время Computex, которая пройдет с 31 мая по 4 июня.
В дополнение к новым техпроцессам, ожидается, что обе новые архитектуры будут использовать различные высокоскоростные памяти, такие как GDDR5x и HBM2, которые обещают улучшенную пропускную способность памяти и ее объем, в случае HBM2. AMD уже успешно выпустила продукт с использованием новой 3DIC памяти в 2015 году с дебютом линейки «Fury».
Хотя циклы слухов о GPU обычно фокусируются на настольных продуктах, генеральный директор AMD заявил, что ожидается запуск как настольных компьютеров, так и ноутбуков с новыми GPU Polaris до начала учебного сезона. Apple традиционно чередовала предложения GPU от AMD и Nvidia для своих линеек продуктов, при этом AMD выиграла последние итерации как 27-дюймовых iMac, так и линеек MacBook Pro.
Особенно MacBook Pro нуждается в обновлении, и слухи предполагают, что новые модели могут появиться на WWDC в июне, но неясно, сможет ли Apple использовать предстоящие GPU в этот период. Apple иногда очень быстро внедряла новейшие технологии от своих партнеров, но иногда ждала довольно долго перед обновлением. Обновления для 27-дюймовых iMac менее ожидаемы, поскольку линейка была только что обновлена до новейших процессоров Intel Skylake в октябре.
Финансовый новостной веб-сайт The Motley Foolподелился деталями чипа A9X, установленного в новом Apple iPad Pro, благодаря анализу от компании по разборке электроники Chipworks. На фотографии показан двухъядерный центральный процессор A9X и 12-кластерный графический процессор для управления большим дисплеем устройства.
Хотя количество ядер центрального процессора в A9X совпадает с количеством ядер в A9 из iPhone 6s и 6s Plus, 12-кластерный графический процессор вдвое мощнее шестикластерного графического процессора, используемого в конструкции A9. В остальном дизайн ядер и кластеров выглядит идентичным тем, что были обнаружены на снимках чипа A9.
Двухъядерный центральный процессор выделен зеленым цветом, шесть двухкластерных областей графического процессора выделены синим цветом
Chipworks подтверждает, что чип, показанный на фотографии, изготовлен TSMC, и он действительно имеет сходство с существующим чипом A9 от TSMC, который ранее был сфотографирован компанией Chipworks.
The Motley Fool также указывает на то, что 8 МБ кэш-памяти третьего уровня, присутствующий в A9 для управления потоком данных к памяти и из нее, отсутствует в чипе A9X. Это позволяет предположить, что отсутствие этого кэша связано с увеличенной пропускной способностью памяти, которую имеет A9X благодаря интерфейсу памяти вдвое большей ширины по сравнению с чипом A9. Действительно, на прилагаемом снимке чипа виден обширный интерфейс памяти DRAM на трех сторонах чипа.
Стоит также отметить, что, несмотря на значительно более высокое разрешение дисплея по сравнению с другими iPad, iPad Pro не оснащен 12-мегапиксельной камерой, как у iPhone 6s и 6s Plus, которая создавала бы дополнительную нагрузку на иерархию памяти для обработки изображений в реальном времени.
Наличие всего двух ядер центрального процессора также представляет интерес, учитывая, что A8X, установленный в iPad Air 2, имел три ядра центрального процессора. iPad Pro может компенсировать любые связанные с этим недостатки производительности за счет сочетания более высокой эффективности, благодаря новой архитектуре, а также значительного увеличения тактовой частоты по сравнению с дизайном A8.
Даже при отсутствии кэша L3 и всего двух ядер центрального процессора, чип A9X имеет площадь 147 квадратных миллиметров. Это всего на 18 квадратных миллиметров меньше, чем у самой большой на сегодняшний день разработки Apple — чипа A5X, установленного в первом iPad с дисплеем Retina. Неудивительно, что A5X был быстро снят с производства и заменен меньшим чипом A6X, используемым в iPad четвертого поколения. Чип A9X с площадью 147 мм² также больше последней четырехъядерной разработки Intel Skylake, площадь которой составляет 122 мм² при использовании 14-нм техпроцесса FinFET.
Хотя это может быть просто идеальным сочетанием экономии площади чипа и достаточной пропускной способности памяти для дизайна A9X, отсутствие кэш-памяти третьего уровня SRAM может повлиять на будущие проектные решения, если пропускная способность памяти значительно улучшится. Технологии 3D-интеграции стремительно входят в сферу потребительской электроники и предлагают разнообразные конфигурации памяти, которые способны значительно увеличить пропускную способность памяти, а также снизить энергопотребление. Как мы сообщали недавно, технологии упаковки, обеспечивающие работу этой высокопроизводительной памяти, могут появиться уже в A10 SoC от Apple для устройств в следующем году.
Biggest design overhaul
since iOS 7 with Liquid Glass, plus new Apple Intelligence features and
improvements to Messages, Phone, Safari, Shortcuts, and more. Developer beta
available now ahead of public beta in July.



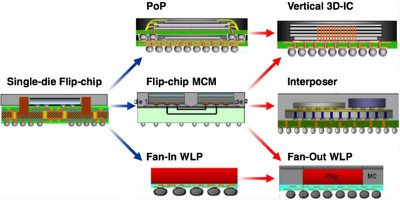
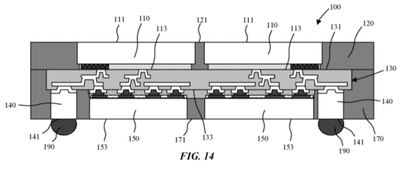
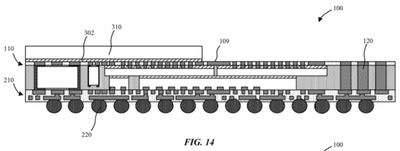
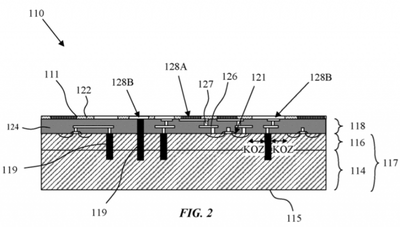



 Влияние на Apple заключается в меньшем количестве обновлений процессоров для линейки продуктов Mac с незначительными улучшениями производительности между последующими поколениями. Apple известна тем, что отказалась от PowerPC из-за его стагнации и отставания в производительности от предложений Intel на базе x86, и теперь ситуация, похоже, повторяется с
Влияние на Apple заключается в меньшем количестве обновлений процессоров для линейки продуктов Mac с незначительными улучшениями производительности между последующими поколениями. Apple известна тем, что отказалась от PowerPC из-за его стагнации и отставания в производительности от предложений Intel на базе x86, и теперь ситуация, похоже, повторяется с 



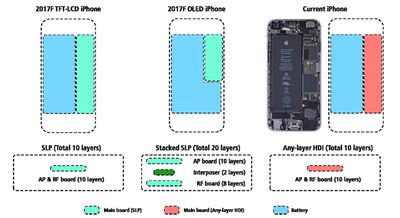



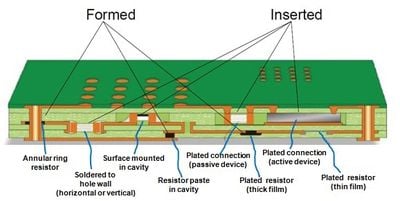


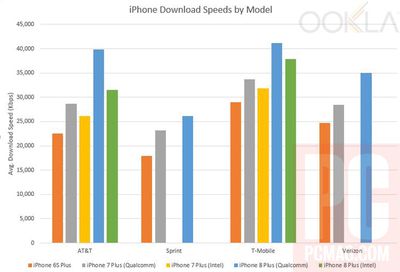

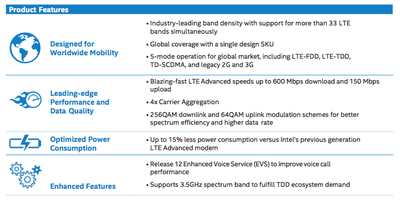

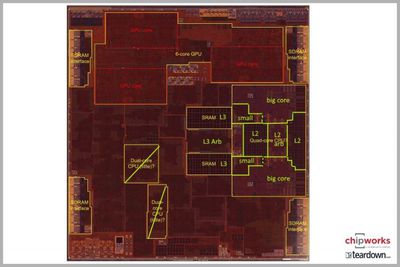
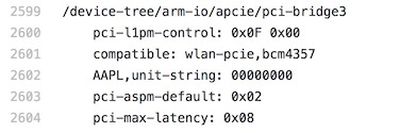









 Одной из ключевых задач для Apple при разработке Apple Watch было обеспечение приемлемого времени автономной работы устройства, несмотря на энергоемкие компоненты, такие как основной процессор и дисплей.
Одной из ключевых задач для Apple при разработке Apple Watch было обеспечение приемлемого времени автономной работы устройства, несмотря на энергоемкие компоненты, такие как основной процессор и дисплей.